
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- LG Aimers 4th
- 딥러닝
- regression
- ChatGPT
- GPT-4
- gpt
- OpenAI
- AI
- 회귀
- Classification
- LLM
- 머신러닝
- PCA
- deep learning
- 해커톤
- supervised learning
- Machine Learning
- 분류
- LG Aimers
- 오블완
- 티스토리챌린지
- LG
- 지도학습
- Today
- Total
SYDev
[데이터베이스] 1장. 데이터베이스 시스템 본문
경희대학교 컴퓨터공학부 이영구 교수님의 데이터베이스 수업자료를 기반으로 작성한 게시물입니다.
데이터베이스 시스템
- 정보와 데이터는 서로 다르다.
- 데이터베이스: 조직체의 응용 시스템들이 공유해서 사용하는 운영 데이터(operational data)들이 구조적으로 통합된 모임이다. 데이터베이스의 구조는 사용되는 데이터 모델에 의해 결정된다.

위와 같은 형태의 데이터가 있을 때, 질의를 통해서 데이터를 정보로 변환한다.
질의: Psychology 수업을 수강한 학생은? -> 정보: Psychology 수업을 수강한 학생은 김철수, 박영희이다.
데이터베이스의 특징
- 데이터베이스는 데이터의 대규모 저장소로서, 여러 부서에 속하는 여러 사용자에 의해 동시에 사용됨
- 모든 데이터가 중복을 최소화하면서 통합됨
- 데이터베이스는 한 조직체의 운영 데이터뿐만 아니라 그 데이터에 관한 설명(데이터베이스 스키마 or 메타데이터(metadata))까지 포함. -> 데이터베이스 스키마(database schema): 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조 (외부 스키마, 내부 스키마, 개념 스키마 3층 구조로 구성)
- 프로그램과 데이터 간의 독립성이 제공됨
- 효율적으로 접근이 가능하고 질의를 할 수 있음
1.1. 데이터베이스 시스템 개요
데이터베이스 스키마
- 데이터베이스 스키마(Database Schema): 전체적인 데이터베이스 구조를 뜻하며, 자주 변경되지는 않음.
- 데이터베이스의 모든 가능한 상태를 미리 정의
- 내포(intension)라고 부름
데이터베이스 상태
- 데이터베이스 상태(Database State): 특정 시점의 데이터베이스 내용을 의미, 시간이 지남에 따라 계속해서 바뀜
- 외연(extension)이라고 부름

데이터베이스 시스템

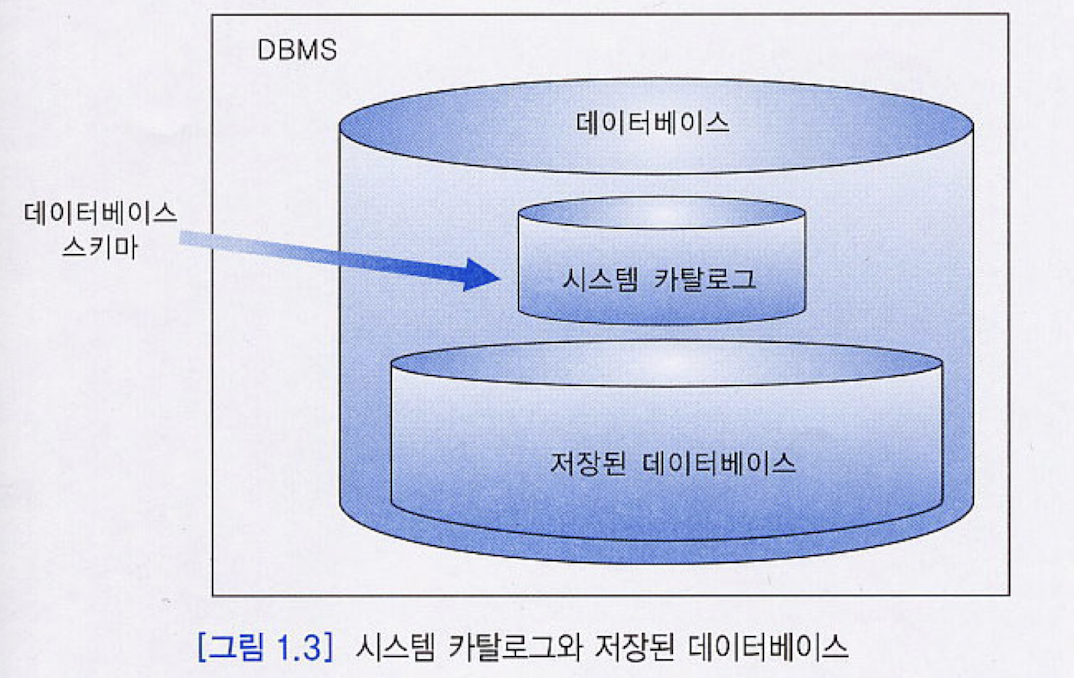
- 데이터베이스 -> 시스템 카탈로그(or 데이터 사전)와 저장된 데이터베이스로 구분할 수 있음
- 시스템 카탈로그(system catalog)는 저장된 데이터베이스의 스키마 정보를 유지
데이터베이스 관리 시스템
- 데이터베이스 관리 시스템(DBMS: Database Management System): 사용자가 새로운 데이터베이스를 생성하고, 데이터베이스의 구조를 명시할 수 있게 하고, 데이터를 효율적으로 질의하고 수정할 수 있도록 하며, 시스템의 고장이나 권한이 없는 사용자로부터 데이터를 안전하게 보호하면서, 동시에 여러 사용자가 데이터베이스에 접근하는 것을 제어하는 소프트웨어
- 데이터베이스 언어라고 부르는 특별한 프로그래밍 언어를 한 개 이상 제공
- SQL은 여러 DBMS에서 제공되는 사실상의 표준 데이터베이스 언어
사용자
- 데이터베이스 사용자는 여러 부류로 나눌 수 있음
하드웨어
- 데이터베이스는 디스크와 같은 보조기억장치에 저장 -> DBMS에서 원하는 정보를 찾기 위해, 디스크 블록들을 주기억장치로 읽어들여야 함 -> 계산이나 비교 연산들을 수행하기 위해 중앙 처리 장치가 사용됨
- DBMS 자체도 주기억 장치에 적재되어 실행되어야 함
데이터베이스 시스템의 요구사항
- 데이터 독립성
- 효율적인 데이터 접근
- 데이터에 대한 동시 접근
- 백업과 회복
- 중복을 줄이거나 제어하며 일관성 유지
- 데이터 무결성
- 데이터 보안
- 쉬운 질의어
- 다양한 사용자 인터페이스
1.2. File System vs. DBMS
File System을 사용한 기존의 데이터 관리
- file system은 DBMS가 등장하지 않은 1960년대부터 사용됨
- file의 기본적인 구성요소 -> 순차적인 레코드들
- 한 레코드 -> 연관된 필드들의 모임
- file에 접근하는 방식이 응용 프로그램 내에 상세하게 표현되므로, 데이터에 대한 응용 프로그램의 의존도가 높음

File System의 단점
- 데이터가 많은 file에 중복해서 저장됨, 다음 형태에서 어떤 사원의 DEPARTMENT 필드 값이 바뀔 때 -> 두 file에서 모두 수정하지 않으면 동일한 사원의 소속 부서가 file마다 다르게 되어 데이터 불일치가 발생

- 다수 사용자들을 위한 동시성 제어가 제공되지 않음
- 검색하려는 데이터를 쉽게 명시하는 질의어가 제공되지 않음
- 보안 조치가 미흡
- 회복 기능이 없음
- 프로그램-데이터 독립성이 없으므로 유지보수 비용이 많이 소요됨
- file을 검색하거나 갱신하는 절차가 상대적으로 복잡하기 때문에 프로그래머의 생산성이 낮음
- 데이터의 공유와 융통성이 부족
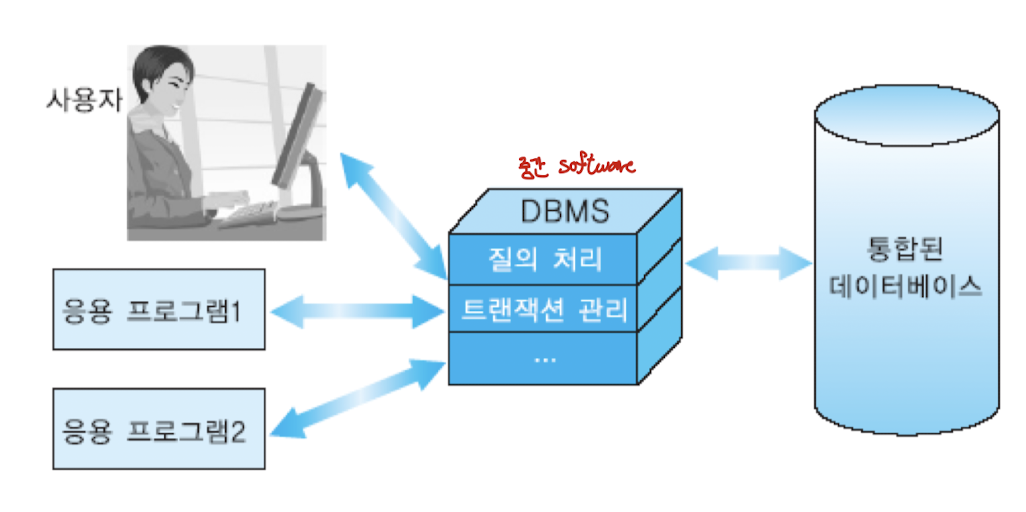
DBMS를 사용한 데이터베이스 관리
- 여러 사용자와 응용 프로그램들이 데이터베이스를 공유
- 사용자의 질의를 빠르게 수행 가능한 인덱스 등의 접근 경로를 DBMS가 자동적으로 선택하여 수행
- 권한이 없는 사용자로부터 데이터베이스를 보호
- 여러 사용자에 적합한 다양한 인터페이스 제공
- 데이터 간의 복잡한 관계를 표현, 무결성 제약조건을 DBMS가 자동적으로 유지
- 시스템이 고장 나면 데이터베이스를 고장 전의 일관된 상태로 회복시킴
- 프로그램에 영향을 주지 않으면서 데이터베이스 구조를 변경할 수 있음 -> 프로그램-데이터 독립성(program-data independence)

DBMS의 장점
- 중복성, 불일치 감소
- 시스템 개발, 유지 비용이 감소 -> 중복되는 기능을 DBMS가 수행해줌
- 표준화 시행하기가 용이
- 보안 향상
- 무결성 향상
- 조직체의 요구사항 식별 가능해짐
- 다양한 유형의 고장으로부터 데이터베이스를 회복 가능해짐
- 데이터베이스의 공유와 동시 접근 가능
DBMS 선정시 고려 사항
기술적 요인
- DBMS에 사용되고 있는 데이터 모델 ex) 대칭 데이터 모델, ...
- DBMS가 지원하는 사용자 인터페이스
- 프로그래밍 언어
- 응용 개발 도구
- 저장 구조
- 성능
- 접근 방법 등
경제적 요인
- 소프트웨어, 하드웨어 구입 비용
- 유지 보수 비용
- 직원들의 교육 지원 등
DBMS의 단점
- 추가적인 하드웨어 구입 비용 발생, DBMS 자체의 구입 비용도 상당함
- 직원들의 교육 비용
- 비밀과 프라이버시 노출 발생 가능성
- 초기의 투자 비용이 너무 클 때, 오버헤드가 너무 클 때, 응용이 단순하고 잘 정의되고 변경되지 않을 것으로 예상될 때, 엄격한 실시간 처리 요구사항이 있을 때, 데이터에 대한 다수 사용자의 접근이 필요하지 않을 때 -> DBMS를 사용하지 않는 것이 바람직할 수 있음
1.3. DBMS 발전 과정
데이터 모델
- 데이터 모델: 데이터베이스의 구조를 기술하는데 사용되는 개념들의 집합인 구조(데이터 타입과 관계), 이 구조 위에서 동작하는 연산자들, 무결성 제약조건들
- 사용자에게 내부 저장 방식의 세세한 사항은 숨기면서 데이터에 대한 직관적인 뷰를 제공하는 동시에 이들 간의 사상을 제공
데이터 모델의 분류
고수준 또는 개념적 데이터 모델(conceptual data model)
- conceptual data model: 사람이 인식하는 것과 유사하게 데이터베이스의 전체적인 논리적 구조를 명시
- ex) 엔티티-관계(ER: Entity-Relationship) 데이터 모델과 객체 지향 데이터 모델

표현(구현) 데이터 모델(representation(implementation) data model)
- 최종 사용자가 이해하는 개념이면서, 컴퓨터 내에서 데이터가 조직되는 방식과 멀리 떨어져 있지는 않음
- ex) 계층 데이터 모델(hierarchical data model), 네트워크 데이터 모델(network data model), 관계 데이터 모델(relational data model)

저수준 또는 물리적 데이터 모델(physical data model)
- physical data model: 데이터베이스에 데이터가 어떻게 저장되는가를 기술
- ex) Unifying, ISAM(Indexed Sequential Acessed Method), VSAM 등


논리적 데이터 모델을 사용하면 프로세스 워크플로를 기술적으로 구조화된 방식으로 시각화할 수 있습니다. 다양한 비즈니스 시스템 간의 관계를 파악할 수 있습니다.
반면, 물리적 데이터 모델은 실제 데이터베이스 테이블에서 데이터가 구성되는 방식을 설명합니다. 애플리케이션이 실제 데이터를 저장하고 액세스하는 방법을 하향식으로 살펴볼 수 있습니다.
https://aws.amazon.com/ko/compare/the-difference-between-logical-and-physical-data-model/
논리적 데이터 모델 대 물리적 데이터 모델 - 데이터 모델링의 차이점 - AWS
논리적 데이터 모델과 물리적 데이터 모델은 데이터 설계의 두 가지 중요한 단계입니다. 데이터 모델링은 다양한 이해 관계자가 조직 데이터에 대한 통합된 뷰를 생성하는 데 도움이 되는 시각
aws.amazon.com

계층 DBMS
- 1960년대 후반, 최초의 계층 DBMS 등장(ex: IBM사의 IMS)
- Hierarchical DBMS: 트리 구조를 기반으로 계층 데이터 모델을 사용한 DBMS
- 계층 데이터 모델은 네트워크 데이터 모델의 특별한 사례
장점
- 제한된 형태의 일부 경우에서만, 빠른 속도와 높은 효율성 제공
단점
- 어떻게 데이터를 접근하는가를 미리 응용 프로그램에 정의해야함
- 데이터베이스가 생성될 때, 각각의 관계를 명시적으로 정의해야 함
- 레코드들이 링크로 연결 -> 레코드 구조 변경이 어려움
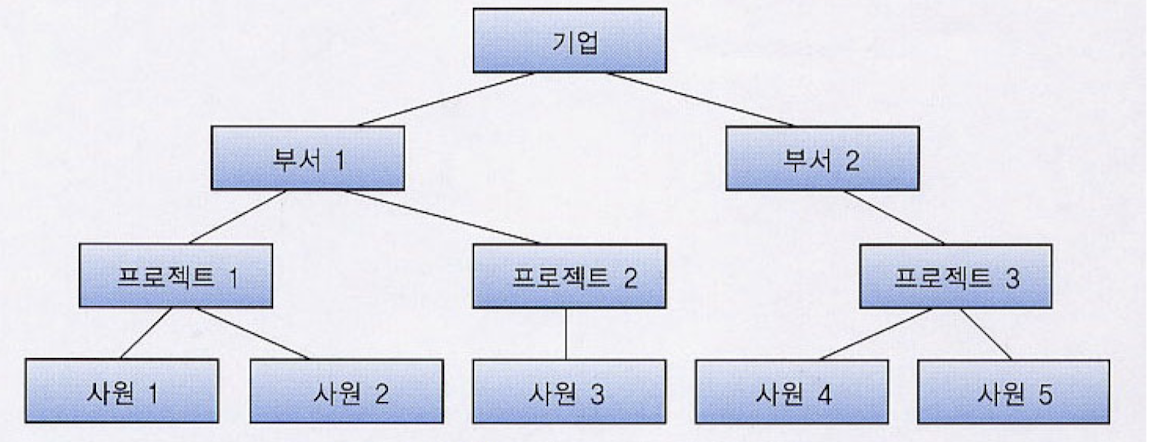
-> one-to-many 관계는 잘 처리하나, many-to-many 관계는 그렇지 못함 -> 부모가 여럿일 수가 없어, 과목-학생과 같은 관계 표현이 어려움
네트워크 DBMS
- 1960년대 초에 Charles Bachman이 Honeywell사에서 최초의 네트워크 DBMS인 IDS를 개발
- 레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 하는 네트워크 데이터 모델을 사용
- 네트워크 DBMS에서도 레코드들이 링크로 연결되어 있으므로 레코드 구조를 변경하기 어려움

관계 DBMS
- 1970년에 E.F. Codd가 IBM 연구소에서 관계 데이터 모델을 제안
- 미국 IBM 연구소에서 진행된 System R과 캘리포니아 버클리대에서 진행된 Ingres 프로젝트
장점
- 모델이 간단하여 이해하기 쉬움
- 사용자가 자신이 원하는 것(what)만 명시하고, 데이터가 어디에 있는지, 어떻게 접근해야 하는지는 DBMS가 결정
ex) 오라클, MS SQL Server, Sybase, DB2, Informix 등
객체 지향 DBMS
- 1980년대 후반 들어 새로운 데이터 모델인 객체 지향 데이터 모델 등장
- 객체 지향 프로그래밍 패러다임을 기반으로 하는 데이터 모델
장점
- 데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉬우며, 유지와 변경이 용이함
ex) ONTOS, OpenODB, GemStone, ObjectStore, VErsant, O2 등
객체 관계 DBMS
- 1990년대 후반에 관계 DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델이 제안됨
ex) 오라클, Informix Universal Server 등

새로운 데이터베이스 응용
- CAD 데이터베이스, 소프트웨어 공학 데이터베이스(재사용이 가능한 소프트웨어들의 라이브러리), 게놈 데이터베이스, 데이터 웨어하우스, 데이터 마이닝, OLAP, 멀티미디어 데이터베이스, 웹 데이터베이스 등
현대의 관계 DBMS
- 효율적인 질의 처리를 지원: 질의 최적화, 인덱싱 등
- 고급 사용자 인터페이스를 지원: SQL, 자연어, 폼 기반 등
- 트랜잭션 개념을 지원: 다수의 트랜잭션을 동시에 실행하고. 백업과 회복을 수행 -> database transaction: 데이터베이스 관리 시스템 or 유사한 시스템에서 상호작용의 단위
- 특별한 데이터 타입을 지원: 긴 필드, 이미지, HTML 링크, 공간 정보 등
- 객체 지향 개념을 지원
- 웹 인터페이스와 XML을 지원 -> XML은 W3C에서 개발된, 다른 특수한 목적을 갖는 마크업 언어를 만드는데 사용하도록 권장하는 다목적 마크업 언어이다.(https://ko.wikipedia.org/wiki/XML)
- 데이터 마이닝 연산들을 지원
- OLAP과 데이터 웨어하우스를 지원 -> OLine Analytic Processing: 데이터 웨어하우스, 데이터 마트 또는 기타 중앙화된 통합 데이터 저장소의 대용량 데이터를 고속으로 다차원 분석하는 소프트웨어 (https://www.ibm.com/kr-ko/topics/olap)

1.4. DBMS 언어
데이터 정의어(DDL: Data Definition Language)
- 사용자는 데이터 정의어를 사용하여 데이터베이스 스키마를 정의
- 데이터 정의어로 명시된 문장이 입력되면 DBMS는 사용자가 정의한 스키마에 대한 명세를 시스템 카탈로그 또는 데이터 사전에 저장
- 데이터 정의어의 기본적인 기능
- 데이터 모델에서 지원하는 데이터 구조를 생성 ex) SQL의 CREATE TABLE
- 데이터 구조의 변경 ex) SQL의 ALTER TABLE
- 데이터 구조의 삭제 ex) SQL의 DROP TABLE
- 데이터 접근을 위해 특정 attribute(속성) 위에 인덱스를 정의 ex) SQL의 CREATE INDEX
데이터 조작어(DML: Data Manipulation Language)
- 사용자는 데이터 조작어를 사용하여 데이터베이스 내의 원하는 데이터를 검색하고, 수정하고, 삽입하고, 삭제
- 절차적 언어(procedural language)와 비절차적 언어(non-procedural language) -> 절차적 언어: 특정 순서대로 데이터를 조작, 비절차적 언어: 과정 설명 없이, 어떤 특정 데이터를 달라 요청
- 관계 DBMS에서 사용되는 SQL은 대표적 비절차적 언어
- 대부분의 데이터 조작어는 SUM, COUNT, AVG와 같은 내장 함수들을 갖고 있음
- 데이터 조작어는 단말기에서 대화식으로 입력되어 수행되거나 C, 코볼 등의 고급 프로그래밍 언어로 작성된 프로그램에 내포되어 사용됨
- 데이터 조작어의 기본적인 기능
- 데이터의 검색 ex) SQL의 SELECT
- 데이터의 수정 ex) SQL의 UPDATE
- 데이터의 삭제 ex) SQL의 DELETE
- 데이터의 삽입 ex) SQL의 INSERT
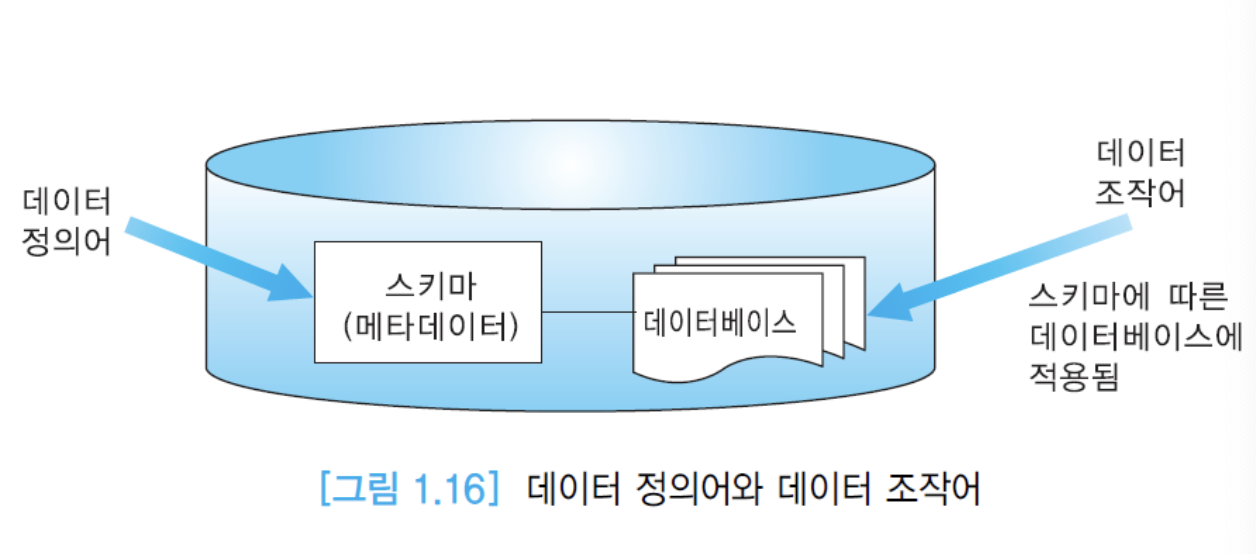

데이터 제어어(DCL: Data Control Language)
- 사용자는 데이터 제어어를 사용하여 데이터베이스 트랜잭션을 명시하고 권한을 부여하거나 취소
1.5. DBMS 사용자

데이터베이스 관리자(DBA: Database Administrator)
- 데이터베이스 관리자: 조직의 여러 부분의 상이한 요구를 만족시키기 위해서 일관성있는 데이터베이스 스키마를 생성하고 유지하는 사람
데이터베이스 관리자의 역할
- 데이터베이스 스키마의 생성과 변경
- 무결성 제약조건을 명시
- 사용자의 권한을 허용하거나 취소하고, 사용자의 역할을 관리
- 저장 구조와 접근 방법(물리적 스키마) 정의
- 백업과 회복
- 표준화 시행
응용 프로그래머
- 데이터베이스 위에서 특정 응용(ex: 고객 관리, 인사 관리, 재고 관리 등)이나 인터페이스를 구현하는 사람
- 고급 프로그래밍 언어인 C, 코볼 등으로 응용 프로그램을 개발하면서 데이터베이스를 접근하는 부분은 내포된 데이터 조작어를 사용
- 이들이 작성한 프로그램은 최종 사용자들이 반복해서 수행 -> 기작성 트랜잭션(canned transaction), 통조림 캔처럼 쉽게 사용 가능
최종사용자(end user)
- 질의, 갱신, 보고서 생성을 위해서 데이터베이스를 사용하는 사람
- 최종 사용자 -> 매번 다른 정보를 찾는 캐주얼 사용자, 기작성 트랜잭션을 주로 반복해서 수행하는 초보 사용자로 구분
데이터베이스 설계자(database designer)
- ERWin 등의 CASE 도구들을 이용해서 데이터베이스 설계를 담당
- 데이터베이스의 일관성을 유지하기 위해서 정규화를 수행
오퍼레이터
- DBMS가 운영되고 있는 컴퓨터 시스템과 전산실을 관리하는 사람
1.6. ANSI/SPARC 아키텍처와 데이터 독립성
ANSI/SPARC 아키텍처
- 현재의 대부분의 상용 DBMS 구현에서 사용되는 일반적인 아키텍처는 1978년에 제안된 ANSI/SPARC 아키텍처
- 물리적, 개념적, 외부 단계로 이루어짐
- 외부 단계(external level): 각 사용자의 뷰
- 개념 단계(conceptual level): 사용자 공동체의 뷰
- 내부 단계(internal level): 물리적 또는 저장 뷰

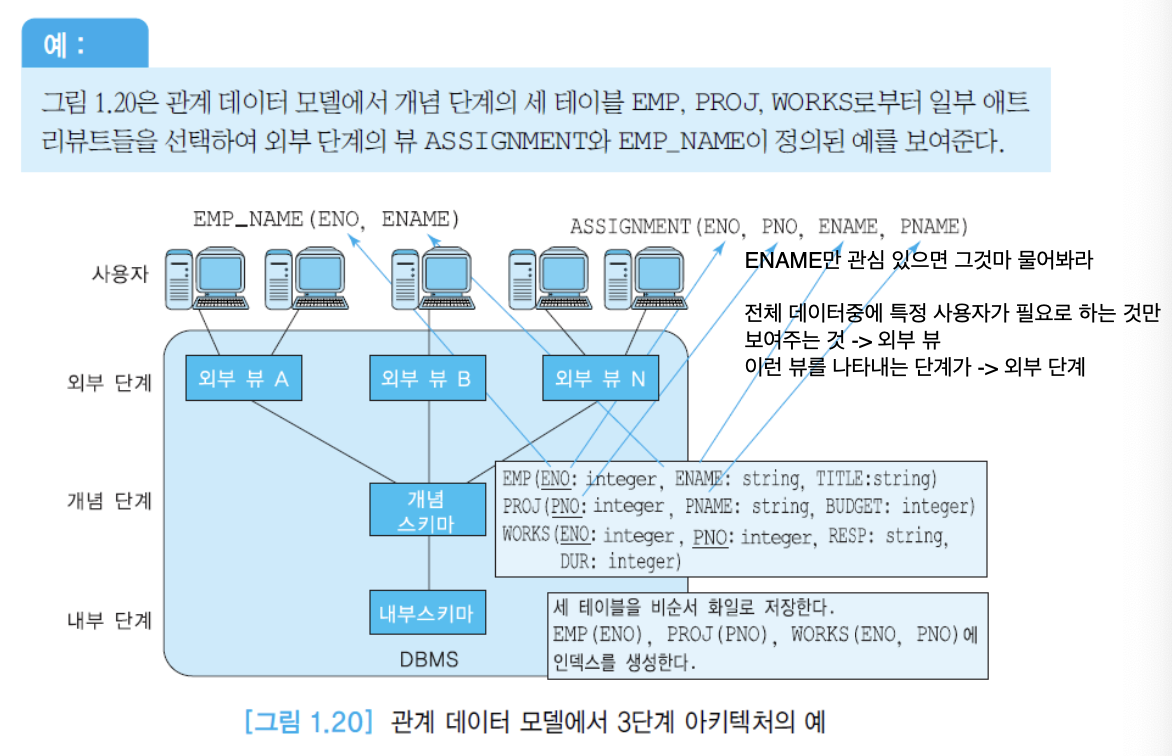
외부 단계
- 데이터베이스의 각 사용자가 갖는 뷰
- 여러 부류의 사용자를 위해 동일한 개념 단계로부터 다수의 서로 다른 뷰가 제공될 수 있음
- 보통 최종 사용자, 응용프로그래머들은 데이터베이스의 일부분에만 관심을 가짐
개념 단계
- 조직체의 정보 모델로서, 물리적인 구현은 고려하지 않으면서 조직체 전체에 관한 스키마를 포함
- 데이터베이스에 어떤 데이터가 저장되어 있는지, 데이터 간에는 어떤 관계가 존재하고 어떤 무결성 제약 조건들이 명시되어 있는지를 기술
- 데이터베이스에 대한 사용자 공동체의 뷰를 나타냄
- 데이터베이스마다 오직 한 개의 개념 스키마가 존재
- 위 예제에서는 개념 단계가 세 테이블 EMP, PROJ, WORKS로 구성
내부 단계
- 실제의 물리적인 데이터 구조에 관한 스키마
- 데이터베이스에 어떤 데이터가 어떻게 저장되어 있는가를 기술
- 인덱스, 해싱 등과 같은 접근 경로, 데이터 압축 등을 기술
- 데이터베이스의 개념 스키마에는 영향을 미치지 않으면서 성능을 향상시키기 위해 내부 스키마를 변경하는 것이 바람직
- 내부 단계 아래는 물리적 단계
- 물리적 단계는 DBMS의 지시에 따라 운영 체제가 관리
- 위 예제에서는 내부 단계에서 EMP 테이블의 ENO attribute, PROJ 테이블의 PNO attribute, WORKS 테이블의 (ENO, PNO) attribute에 인덱스가 정의됨
스키마 간의 사상
- DBMS는 세 가지 유형의 스키마 간의 사상을 책임짐
외부/개념 사상(external/conceptual mapping)
- 외부 단계의 뷰를 사용해서 입력된 사용자의 질의를 개념 단계의 스키마를 사용한 질의로 변환
- ENO/ENAME만 요청했을 때, 그 정보만을 추출해서 보여주는 것 -> 외부/개념 사상에서 처리
개념/내부 사상(conceptual/internal mapping)
- 이를 다시 내부 단계의 스키마로 변환하여 디스크의 데이터베이스를 접근
- 물리적 저장 공간에 있는 것을 내부 단계의 스키마로 변환하여 디스크의 데이터베이스를 접근 -> 데이터 독립성 제공, 개념/내부 사상
데이터 독립성
- 상위 단계의 스키마 정의에 영향을 주지 않으면서, 어떤 단계의 스키마 정의를 변경할 수 있음을 의미
논리적 데이터 독립성
- 논리적인 데이터 독립성(logical data independence): 개념 스키마의 변화로부터 외부 스키마가 영향을 받지 않음을 의미
- 기존의 외부 스키마에 영향을 미치지 않고, 응용 프로그램을 다시 작성할 필요 없이 개념 스키마에 대한 변화가 가능해야 함
물리적 데이터 독립성
- 물리적인 데이터 독립성(physical data independence): 내부 스키마의 변화가 개념적 스키마에 영향을 미치지 않으며, 따라서 외부 스키마(혹은 응용 프로그램)에도 영향을 미치지 않음을 의미
- 내부 스키마 변화 예시: file의 저장 구조를 바꾸거나 인덱스를 생성 및 삭제

1.7. 데이터베이스 시스템 아키텍처

데이터 정의어 컴파일러(DDL compiler) 모듈
- 데이터 정의어를 사용해 테이블 생성 요청 -> 테이블을 파일 형태로 데이터베이스에 생성 -> 이 테이블에 대한 명세를 시스템 카탈로그에 저장
시스템 카탈로그: 시스템 그 자체에 관련이 있는 다양한 객체에 관한 정보를 포함하는 시스템 데이터베이스
-> 시스템 카탈로그 내의 각 테이블: 사용자를 포함하여 DBMS에서 지원하는 모든 데이터 객체에 대한 정의, 명세에 관한 정보를 유지관리하는 시스템 테이블
- 카탈로그 자체도 시스템 테이블로 구성되어 있어, 일반 이용자도 SQL을 이용해 내용 검색 가능
- INSERT, DELETE, UPDATE문으로 카탈로그 갱신은 허용 X
- DBMS가 스스로 생성하고 유지
- 데이터베이스 시스템에 따라 상이한 구조
https://coding-factory.tistory.com/225
질의 처리기(query processor) 모듈
- 데이터 조작어를 수행하는 최적의 방법을 찾는 모듈을 통해서 기계어 코드로 번역
런타임 데이터베이스 관리기(run-time database manager) 모듈
- 디스크에 저장된 데이터베이스를 접근
트랜잭션 관리(transaction management) 모듈
- 동시성 제어(concurrency control) 모듈
- 회복(recovery) 모듈
데이터베이스 API(Application Program Interface)
ODBC(Open Database Connectivity)
- 마이크로소프트사가 주도적으로 개발한 데이터베이스 API
- ODBC를 지원하는 DBMS 간에는 서로 상대방의 데이터베이스를 접근할 수 있음
JDBC(Java Database Connectivity)
- 자바 프로그램에서 해당 데이터베이스에 접근 가능

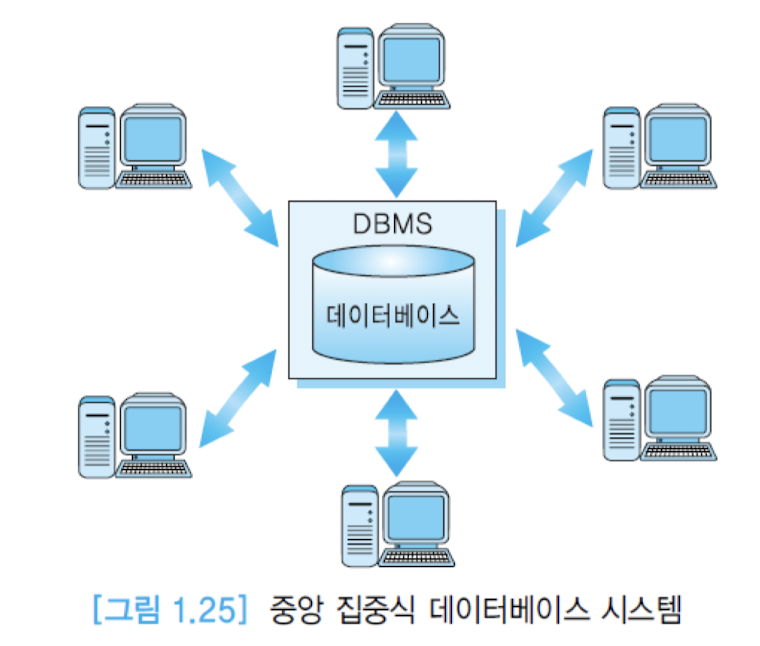
중앙 집중식 데이터베이스 시스템(Centralized Database System)
- 데이터베이스 시스템이 하나의 컴퓨터 시스템에서 운영됨
분산 데이터베이스 시스템(Distributed Database System)
- 네트워크로 연결된 여러 사이트에 데이터베이스 자체가 분산됨 -> 데이터베이스 시스템도 여러 컴퓨터 시스템에서 운영됨
- 사용자는 다른 사이트에 저장된 DB에도 접근 가능
- 여러 머신에 설치가 되어있고, 협력해서 거대한 DB를 만듦

클라이언트-서버 데이터베이스 시스템(Client-server Database System)
- PC or 워크스테이션처럼 자체 컴퓨팅 능력을 가진 client를 통해 데이터베이스 서버를 접근
- 데이터베이스가 하나의 데이터베이스 서버에 저장됨
- 데이터베이스 시스템 기능 -> 서버, 클라이언트에 분산됨
- 서버-> 데이터베이스 저장, DBMS를 운영하면서 여러 클라이언트에서 온 질의를 최적화, 권한 검사 수행, 동시성 제어와 회복 기능, 데이터베이스 무결성 유지, 데이터베이스 접근을 관리
2층 모델(2-tier model)
- 클라이언트와 데이터베이스 서버가 직접 연결
3층 모델(3-tier model)
- 클라이언트와 데이터베이스 서버 사이에 응용 서버가 추가됨
- 응용 서버에는 응용 논리가 있다 -> 조직마다 특정 비즈니스 logic 존재


장점
- 데이터베이스를 보다 넓은 지역에서 접근할 수 있음
- 다양한 컴퓨터 시스템 사용 가능
단점
- 보안이 다소 취약할 수 있음
참고자료
- 『데이터베이스 배움터』, 홍의경 지음, 생능출판, 2012년 08월 29일
'3학년 1학기 전공 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 5.1. 데이터베이스 설계의 개요 (0) | 2024.05.02 |
|---|---|
| [데이터베이스] 4장. 관계대수와 SQL - 2 (0) | 2024.04.24 |
| [데이터베이스] LAB4-sql_6 (0) | 2024.04.14 |
| [데이터베이스] 4장. 관계 대수와 SQL (0) | 2024.03.20 |
| [데이터베이스] 2장. 관계 데이터 모델과 제약 조건 (3) | 2024.03.14 |



