
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- regression
- 해커톤
- deep learning
- AI
- 티스토리챌린지
- 딥러닝
- 회귀
- 분류
- ChatGPT
- GPT-4
- LLM
- LG
- 지도학습
- Classification
- 머신러닝
- PCA
- LG Aimers
- gpt
- supervised learning
- OpenAI
- 오블완
- Machine Learning
- LG Aimers 4th
Archives
- Today
- Total
SYDev
MongoDB 기본 개념 본문
MongoDB의 기본 개념에 대해 알아보자.
이번에는 MongoDB에 대한 기본 개념에 대해서 알아보겠습니다. 이번 시간에는 각 주제별 자세한 내용을 다루기보다는 mongoDB에 대한 전체적인 개념을 파악하는데 초점을 두었습니다. 😊 1. mongoDB
ryu-e.tistory.com
위 게시물을 기반으로 한 단순 공부용 포스팅!!
MongoDB?
- MongoDB: document 지향적인 database
- document: field:value 형식으로 구성된 데이터 구조
- value에는 문자열, 숫자 날짜 , 배열, 다른 도큐먼트를 저장하는 것이 가능

- Schema-less 구조 -> 스키마를 고정하지 않은 형태로, 필드 추가 및 제거가 편리
- 분산 확장이 간단 -> 샤딩 시스템, 샤딩: 샤드(분산하는 각각의 장비)에 걸쳐 있는 데이터를 분할하는 처리)
JSON vs BSON
- MongoDB에서는 JSON, BSON type 모두 사용
- JSON: javascript 형식의 오브젝트 표기법 -> mongoDB에서 Document를 저장하는 형태와 동일
- BSON
- mongoDB에서 JSON 데이터를 DB 내에 저장할 때, BSON 타입의 바이너리 형태 데이터로 반환시켜 저장
- BSON -> Binary JSON: JSON 문서를 바이너리로 인코딩한 포맷
- JSON과 비교하여 BSON은 스톨지ㅣ 공간과 스캔 속도 모두에서 효율적으로 설계
mongoDB 용어
| RDBMS | mongoDB |
| Database | Database |
| Table | Collection |
| Row | Document |
| Index | Index |
| DB server | Mongod |
| DB client | mongo |
기본 쿼리
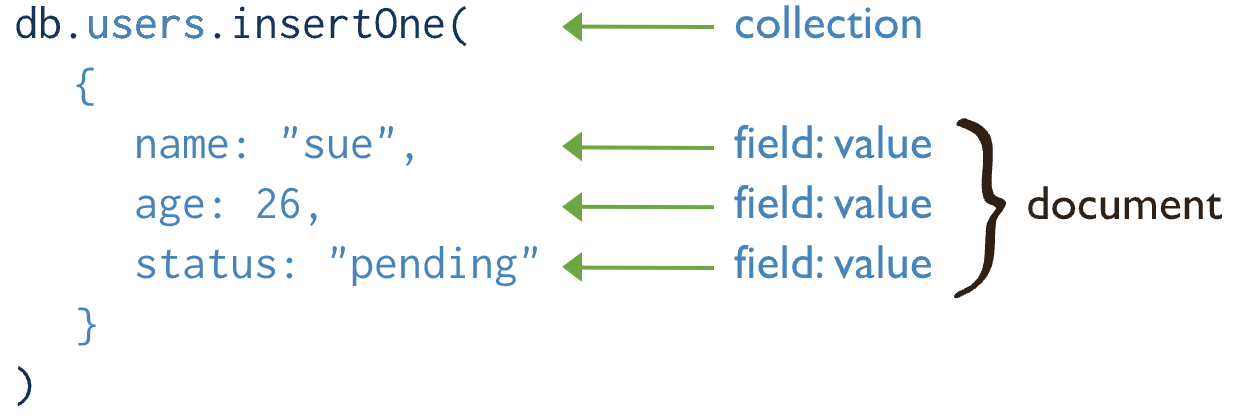
1. C(Create) - insert
- db.collection.insertOne()
- db.collection.insertMany()
2. R(Read) - find
- db.collection.find()

3. U(Update) - update
- db.collection.updateOne()
- db.collection.updateMany()
- db.collection.replaceOne()

4. D(Delete) - delete
- db.collection.deleteOne()
- db.collection.deleteMany()

Index
- Index: Query를 더욱 효율적으로 할 수 있도록 documents에 기준(key)을 정해 정렬된 목록을 생성
- 인덱스가 없다면 -> 전수탐색 방식으로 스캔
- Hash index를 제외하고, MongoDB는 B-Tree 구조로 indexing됨
- 기본 index: 모든 mongoDB의 collection은 기본적으로 _id 필드에 인덱스가 존재
- _id 인덱스는 unique, mongoDB client가 같은 _id를 가진 문서를 중복적으로 추가하는 것을 방지
1. 생성
- 값을 1로 하면 오름차순, -1로 하면 내림차순 정렬
- db.collection.createIndex( { key: 1 } )
2. 조회
- db.collection.getIndexes()
3. 제거
- db.collection.dropIndex( { key: 1 } )
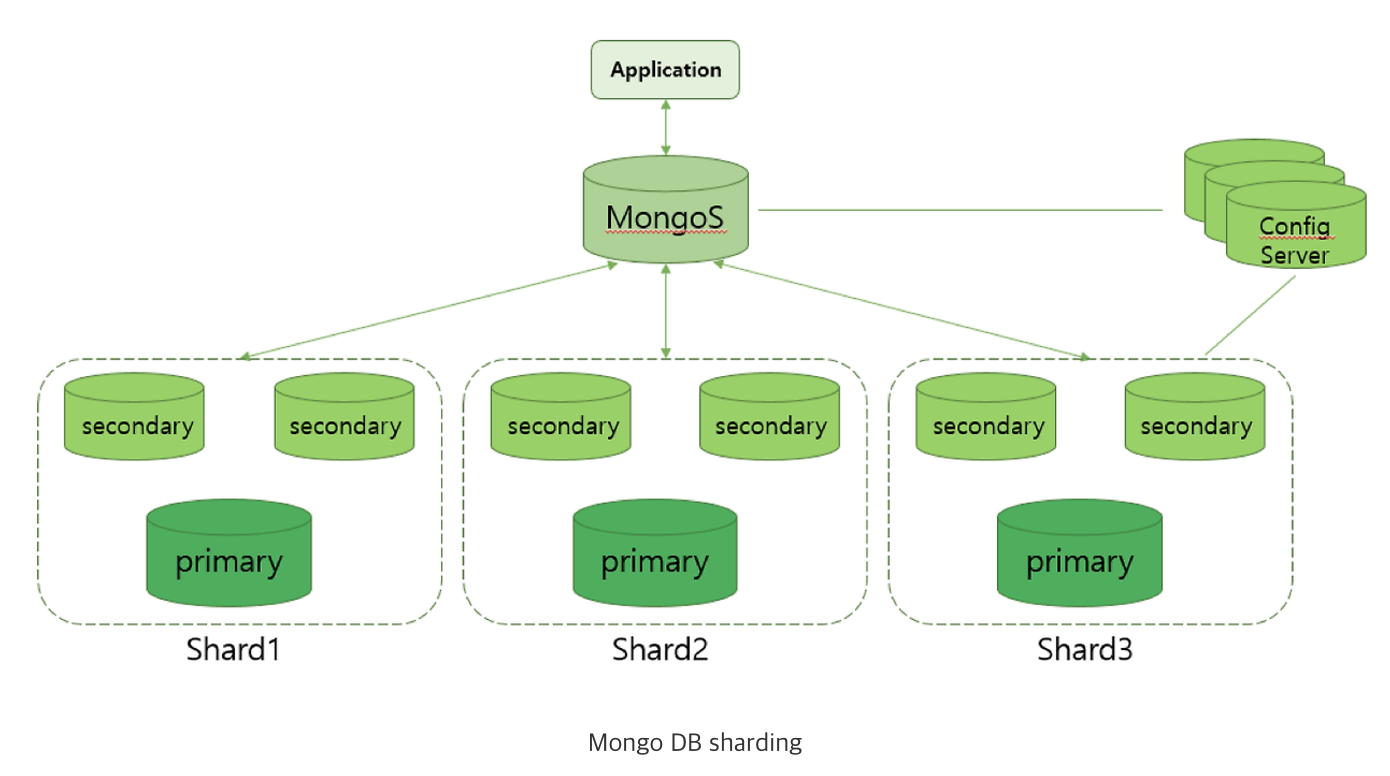
Sharding
- Sharding: 대규모의 데이터를 insert하면 write scaling 문제 발생하여 서비스 성능 저하 -> 여러 대의 서버에 분산 처리
- 여러 대의 독립된 프로세스가 병렬로 작업을 동시에 수행 -> 이상적으로 빠른 처리 성능을 보장
- 하나의 서버에서 관리를 하면 유실 시에 큰 손실 -> 분산 처리로 이런 위험 요소로부터 안전하게 데이터 저장, 관리

참고자료
MongoDB의 기본 개념에 대해 알아보자.
이번에는 MongoDB에 대한 기본 개념에 대해서 알아보겠습니다. 이번 시간에는 각 주제별 자세한 내용을 다루기보다는 mongoDB에 대한 전체적인 개념을 파악하는데 초점을 두었습니다. 😊 1. mongoDB
ryu-e.tistory.com
MongoDB CRUD Operations - MongoDB Manual v8.0
CRUD operations create, read, update, and delete documents.You can connect with driver methods and perform CRUD operations for deployments hosted in the following environments:Create or insert operations add new documents to a collection. If the collection
www.mongodb.com
728x90
반응형
'3학년 2학기 전공 > 풀스택서비스프로그래밍' 카테고리의 다른 글
| [풀스택서비스프로그래밍] Lecture 02. RESTful API Client & Server 개발 (2) | 2024.10.01 |
|---|---|
| [풀스택서비스프로그래밍] Lecture 01. Dart 언어의 이해(심화) - part2 (0) | 2024.09.25 |
| [풀스택서비스프로그래밍] parallelism vs concurrency (0) | 2024.09.23 |
| [풀스택서비스프로그래밍] Lecture 01. Dart 언어의 이해(심화) - part1 (1) | 2024.09.16 |
| [풀스택서비스프로그래밍] Lecture 01. Dart 언어의 이해(기초) (2) | 2024.09.16 |
'3학년 2학기 전공/풀스택서비스프로그래밍' Related Articles
more


