
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- supervised learning
- OpenAI
- LG
- gpt
- PCA
- deep learning
- ChatGPT
- 분류
- Machine Learning
- 티스토리챌린지
- 회귀
- 지도학습
- LG Aimers 4th
- GPT-4
- 해커톤
- LLM
- LG Aimers
- 오블완
- 딥러닝
- 머신러닝
- Classification
- AI
- regression
- Today
- Total
SYDev
[네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(2) 본문
[네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(2)
시데브 2023. 9. 27. 17:15본 게시물은 네이버 부스트 캠프 cv 강의(https://www.boostcourse.org/ai340/joinLectures/369545)를 기반으로 작성된 게시물입니다.
Object Detection
- Object Detection: 특정 물체의 위치를 Bounding Box로 예측하고, 해당 물체의 클래스까지 분류해내는 task이다.
- 최근의 Object Detection은 Two Stage Detector와 One Stage Detector로 나뉘어 빠르게 발전하고 있다.
- One-stage Detector는 Classification과 Localization 문제를 한 번에 해결하는 방법이고, Two-stage Detector는 이를 순차적으로 해결한다.


Two-stage Detector
R-CNN
- R-CNN(Regions with Convolutional Neural Networks features): 설정한 region을 CNN의 feature로 활용하여 Object Detection을 진행.

1. 이미지에 있는 데이터와 레이블을 투입하여 물체의 영역을 탐색(selective search) -> Regional Proposal Output (~2000개)
2. 추출한 regional proposal output을 모두 동일 input size로 만들어주기 위해 warping을 진행.
(convolution layer에서는 input size가 중요하지 않으나, FC layer에서는 input size가 같아야 하므로, convolution layer에 애초에 같은 input size를 넣어서 output size도 같게 만들어준다.)
3. warping한 regional proposal output을 CNN 모델에 투입
4. CNN으로 추출한 feature map을 SVM으로 classification
Selective Search

1. 색상, 질감, 영역크기 등을 이용해 non-objective segmentation을 수행
2. Bottom-up 방식으로 small segmented areas들을 합쳐서 더 큰 segmented areas들을 생성
3. (2)작업을 반복하여 최종적으로 2000개의 region proposal을 생성
Fast R-CNN
- R-CNN은 하나의 Region-Proposal마다 각각 연산을 진행하기 때문에 시간이 오래 걸린다.
- R-CNN은 ene-to-end network가 아니기 때문에 학습을 통한 성능 향상에 제한이 있다.
- 이러한 문제를 해결하기 위해 고안된 Fast-RCNN
1. region proposal 추출 -> 전체 image CNN 연산 -> RoI Projection, RoI Pooling
2. Classification, Bounding Box Regression

>> RoI pooling을 사용하여 R-CNN에 비해 약 18배 빠른 속도 달성
Spatial Pyramid Pooling
- FC Layers의 input에서나 size가 중요하지 CNN에서는 상관이 없기 때문에, FC Layers에 들어가기 전에만 size를 맞춰준다.
- Input Image를 먼저 CNN에 통과시킨 feature map을 전부 똑같이 bin으로 나누면, feature를 고정된 size로 압축 가능하다. -> 2000번의 CNN연산이 1번으로 줄어

RoI pooling
- CNN연산으로 나온 feature map에 selective search를 통해 찾은 RoI(region proposal)를 projection
- 각 bin에 max pooling을 진행시켜 고정된 feature vector를 구한다.

end-to-end : Trainable
- R-CNN 모델에서는 localization 과정의 bounding box regression에는 CNN을 거치기 전의 RoI가 입력되고, classification 과정의 SVM 모델에는 CNN을 거친 후의 RoI가 입력되어 연산이 공유되지 않았다.
- Fast R-CNN에서는 RoI Pooling 과정으로 RoI를 feature map에 투영시킬 수 있게 되어 동일 데이터가 두 모델에 입력되어 연산을 공유할 수 있다.
- 이는 모델이 end-to-end 방식으로 한 번에 학습이 가능해졌다는 뜻

Faster R-CNN
- Fast R-CNN도 여전히 selective research를 CNN 외부에서 연산하여 속도가 저하되는 문제 존재
- Faster R-CNN에서는 detection에서 쓰인 conv feature을 RPN에서도 공유해서 RoI생성역시 CNN level에서 수행하여 속도를 향상
- Faster R-CNN은 Fast R-CNN구조에서 conv feature map과 RoI Pooling사이에 RoI를 생성하는 Region Proposal Network가 추가된 구조
- RPN + Fast R-CNN

..+
One-stage Detector
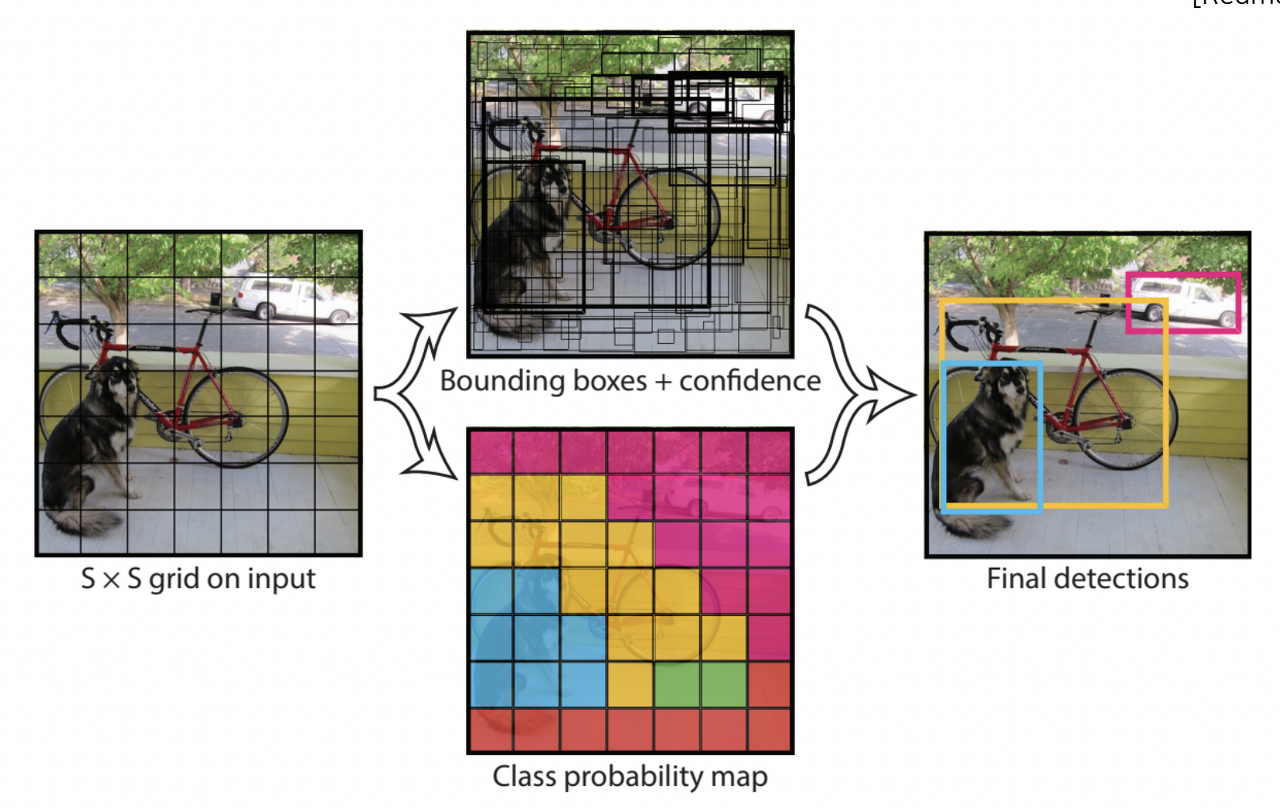
YOLO(You Only Look Once)
입력 이미지를 SXS의 그리드로 분할 -> 각 그리드에 대해 Confidence Score, Classification Score 예측 -> NMS를 통해 정리된 Bbox만 출력
SSD (Single Shot MultiBox Detector)
- SSD는 multi-scale object들을 더욱 잘 처리하기 위해 중간 feature들을 잘 고려한 bounding box를 출력할 수 있도록 동작

Single-stage Detector vs Two-stage Detector
Focal Loss
- 불균형 문제를 완화하기 위해 cross-entropy loss의 확장된 개념이라고 볼 수 있는 focal loss가 제안

RetinaNet
- 이전에 다뤘던 U-Net과 매우 비슷한 방식으로 low-level의 특징과 high-level의 특징을 잘 고려하면서도 multi-scale object를 잘 탐지하기 위해 제안된 구조
- U-Net과는 다르게 concatenation이 아니라 합해주는 방식을 취하고, classification head와 box head가 따로 구성되어있어 별도로 각각을 수행
DETR
- NLP 분야에서 큰 성공을 거둔 Transformer 구조를 computer vision 분야에서 활용할지에 대한 연구
- 먼저 CNN을 통해 입력 이미지의 특징을 추출하고 positional encoding과 함께 더하여 transformer encoder의 입력 토큰으로 넣어줌
- Encoder의 출력으로 얻은 임베딩을 transformer decoder에서 attention 계산시 활용하고, decoder의 입력으로는 object query를 사용
- object query는 querying을 위해 사전에 학습된 positional encoding
- Transformer decoder가 입력된 object query에 해당하는 object가 무엇인지에 대한 정보를 출력하며, 그 정보를 prediction heads(FFN)을 거쳐 최종적으로 어떤 object인지, 그리고 object가 있다면 그 bounding box의 위치까지 출력하는 구조
참고자료
컴퓨터 비전의 모든 것
부스트코스 무료 강의
www.boostcourse.org
(논문리뷰) R-CNN 설명 및 정리
컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmentation 4. Visual relationship 이중에서 4. Visual relationship은 나중에 다루고 먼저 위 3개의 차이를
ganghee-lee.tistory.com
R-CNN 을 알아보자
딥러닝(CNN)을 Object Detection 분야에 최초로 적용시킨 모델이며 이전의 Object Detection 모델에서 성능을 상당히 향상시키고, 이후 Fast R-CNN, Faster R-CNN, Mask R-CNN을 나오게 한 의미있는 모델인 R-CNN에 대
velog.io
(논문리뷰) Fast R-CNN 설명 및 정리
이전글 : (논문리뷰) R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmentation 4. Visual relation
ganghee-lee.tistory.com
(논문리뷰&재구현) Faster R-CNN 설명 및 정리
이전글 : (논문리뷰) Fast R-CNN 설명 및 정리 Fast R-CNN 설명 및 정리 이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할
ganghee-lee.tistory.com
[논문 리뷰] SPPNet(2014) 설명 (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
R-CNN에 이어 SPPNet 논문을 리뷰합니다. 사실 SPPNet은 풀링기법을 제안하는 논문이라서 object detection뿐만 아니라 CNN에 전부 적용할 수 있지만, R-CNN에서의 큰 단점을 커버하면서 추천되는 object detecti
inhovation97.tistory.com
(논문리뷰) Fast R-CNN 설명 및 정리
이전글 : (논문리뷰) R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmentation 4. Visual relation
ganghee-lee.tistory.com
(논문리뷰&재구현) Faster R-CNN 설명 및 정리
이전글 : (논문리뷰) Fast R-CNN 설명 및 정리 Fast R-CNN 설명 및 정리 이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할
ganghee-lee.tistory.com
'KHUDA 4th > Computer Vision' 카테고리의 다른 글
| [KHUDA 4th] CV 4주차 세션 (10.04) (1) | 2023.10.05 |
|---|---|
| [KHUDA 4th] CV 2주차 세션 (09.27) (0) | 2023.09.28 |
| [네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(1) (0) | 2023.09.26 |
| Convolution Neural Network(합성곱 신경망) (0) | 2023.09.24 |
| [네이버 부스트 코스] 2. 데이터 부족 문제 완화 (0) | 2023.09.20 |



