
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Classification
- Machine Learning
- OpenAI
- 오블완
- 딥러닝
- GPT-4
- AI
- 분류
- PCA
- ChatGPT
- supervised learning
- deep learning
- regression
- LG Aimers
- gpt
- 회귀
- 티스토리챌린지
- LLM
- 해커톤
- LG
- 지도학습
- LG Aimers 4th
- 머신러닝
- Today
- Total
SYDev
Chapter 02-2: 데이터 전처리 본문
넘파이로 데이터 준비
넘파이를 이용해서 이전보다 간편하게 데이터를 준비할 수 있다.
np.column_stack() 및 훈련 데이터 준비
array([[1, 4],
[2, 5],
[3, 6]])-> np.column_stack() 함수는 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다. 연결할 리스트는 파이썬 튜플(tuple)로 전달한다.
튜플은 리스트처럼 원소에 순서가 있지만 수정할 수 없다는 차이점이 있다.
-> 훈련 데이터는 길이, 무게 샘플들이 np.column_stack() 함수가 적용된 형태의 numpy 배열
np.concatenate() 및 타깃 데이터 준비
함수 np.concatenate()는 전달받은 리스트를 첫 번째 차원을 따라 배열을 연결한다.
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]-> 타깃 데이터는 길이, 무게 샘플들이 np.concatenate() 함수가 적용된 형태의 numpy 배열
사이킷런으로 훈련 세트와 테스트 세트 나누기
-> train_test_split() 함수는 전달되는 리스트나 배열을 비율에 맞게(테스트 세트의 디폴트는 전체의 25%) 훈련 세트와 테스트 세트로 나누어 준다.
(36, 2) (13, 2)
(36,) (13,)-> 훈련 데이터 36개, 테스트 데이터 13개, 입력 데이터 2차원 배열, 타깃 데이터 1차원 배열
+ 넘파이 배열의 크기는 파이썬의 튜플로 표현되는데, 튜플은 원소가 하나이면 뒤에 콤마를 추가
train_test_split()함수를 이용한 샘플링 편향의 해결
[1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]테스트 세트의 원래 도미, 빙어 비율은 2.5:1이다. 그러나, 도미와 빙어의 비율이 위와 같이 3.3:1로 샘플링 편향이 일어났다.
이를 해결하기 위해서 train_test_split()함수의 매개변수인 stratify를 조정해줄 수 있다.
[0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
거리 비율의 문제
문제 제기
1.0
[0.]
그림을 대충 봤을 때는 삼각형에 해당하는 샘플이 도미로 판정되는 것이 맞아보이지만, 모델은 해당 샘플이 빙어라고 판단한다. 왜 이런 문제가 발생할까?
해당 KNeighborsClassifier의 이웃 개수인 n_neighbors의 기본값이 5이므로 해당 샘플의 주변 5개 샘플을 찾아보자.
-> kneighbors()는 가장 가까운 이웃 샘플까지의 거리와 인덱스를 반환하는 함수

-> kneighbors()의 반환값으로 나온 이웃샘플이 대부분 빙어의 그룹에 속해있다. 이를 인덱스로 확인해보자.
[[1. 0. 0. 0. 0.]]마지막으로 이웃샘플까지의 거리를 확인해보자.
[[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]-> 그래프 상에서 가장 가까운 이웃샘플과의 거리가 92인데, 두 번째로 먼 이웃샘플과의 거리가 130이다. 이 문제는 x축과 y축의 범위가 다르기 때문에 발생한다.
다음과 같이 x축의 범위를 y축과 똑같이 0에서 1000으로 맞추면 문제점이 파악된다.

데이터 전처리를 이용한 모델 훈련
- 위 문제를 두 특성의 스케일(scale)이 다르다고 한다.
- 이런 문제를 해결하기 위해서 특성값을 일정한 기준에 맞추는 작업인 데이터 전처리가 필요하다.
- 가장 널리 사용하는 전처리 방법 중 하나는 표준점수(standard score)이다.
- 표준점수: 특성의 평균을 빼고 표준편차로 나눈 값, 반드시 훈련 세트의 평균과 표준편차로 테스트 세트를 바꿔야 한다.
[ 27.29722222 454.09722222] [ 9.98244253 323.29893931]-> 특성마다 값의 스케일이 다르므로, 평균과 표준편차는 각 특성별로 계산해야 한다. axis=0으로 인해서 행을 따라 각 열의 평균과 표준편차가 계산된다.
-> 브로드캐스팅에 의해 모든 각각의 행에서 계산이 진행된다.
- 브로드캐스팅(broadcasting): 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능

-> 새로 주어진 샘플인 [25, 150]을 동일한 비율로 변환하지 않으면 그림과 같이 출력된다.

-> x축과 y축의 범위가 바뀐 것을 제외하면, 표준편차로 변환하기 전 산점도와 거의 일치한다.
1.0
[1.]-> 바뀐 데이터셋으로 모델을 다시 훈련하니 아까는 빙어로 판정되던 샘플이 이번에는 도미로 올바르게 판정되었다.
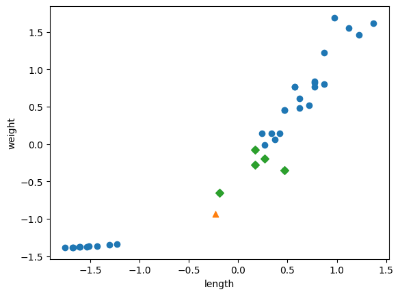
-> 아까와는 달리 문제의 샘플의 이웃샘플이 모두 도미로 판정된다. 따라서 모델은 해당 샘플을 도미라고 판단한다.
참고자료
- 박해선, <혼자 공부하는 머신러닝+딥러닝>, 한빛미디어(주), 2022.2.4
'KHUDA 4th > 머신러닝 기초 세션' 카테고리의 다른 글
| Chapter 03-2: 선형 회귀 (0) | 2023.08.03 |
|---|---|
| Chapter 03-1: k-최근접 이웃 회귀 (0) | 2023.08.03 |
| [KHUDA 4th] 머신러닝 1주차 기초 세션 (08.02) (0) | 2023.08.03 |
| Chapter 02-1: 훈련 세트와 테스트 세트 (0) | 2023.07.30 |
| Chapter 01-3: 마켓과 머신러닝 (0) | 2023.07.30 |



