
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- PCA
- 딥러닝
- 머신러닝
- regression
- supervised learning
- gpt
- deep learning
- 티스토리챌린지
- LLM
- LG Aimers 4th
- 오블완
- LG
- Machine Learning
- Classification
- 회귀
- 지도학습
- GPT-4
- ChatGPT
- 분류
- LG Aimers
- 해커톤
- AI
- OpenAI
- Today
- Total
SYDev
[네이버 부스트 코스] 1. 컴퓨터 비전의 시작 본문
본 게시물은 네이버 부스트 캠프 cv 강의(https://www.boostcourse.org/ai340/joinLectures/369545)를 기반으로 작성된 게시물입니다.
컴퓨터 비전의 개념과 역사에 대해 배우고,
cv task의 backbone network로 활용되는 CNN에 대해 이해해보자.
Neural Network
- Neural Network(인공신경망): 실제 인간의 뇌 신경망을 모방한 것으로 Deep Learning은 이를 이용한 "알고리즘"으로 머신러닝을 최종적으로 실현하는 것이다.
- 뇌에서 각 뉴런은 수상돌기(입력)을 통해 다른 뉴런에서 신호를 받아 축삭돌기(출력)에서 신호를 보낸다.

- neural network에서 동일선상에 있는 하나의 세로 줄을 Layer라 한다.
- Input layer부터 output layer까지 순서대로 변수들을 계산하고 저장하는 것을 Forward Propagation이라 한다.
Computer Vision이란?
- 컴퓨터 비전(computer vision): 시각 지각 능력(Visual perception & intelligence)을 컴퓨터 시스템으로 구현하는 것을 의미한다.
- 과거에는 input의 feature extraction 과정을 사람이 직접 했지만, 현대의 딥러닝 방법론에서는 입출력 쌍만 주어지면 end-to-end로 학습하는 방식을 이용한다. -> 효율성과 성능 모두 상



Image Classification
- Image Classification: 주어진 입력 이미지를 특정 클래스로 분류하는 task로, cv에서 가장 간단하면서도 중요한 문제라고 할 수 있다.
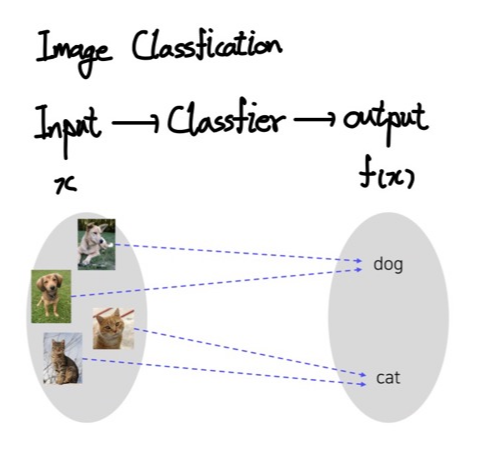
이미지 분류의 구현
- 분류기가 세상의 모든 이미지 데이터를 저장하고 있다 가정하면, K-NN 알고리즘으로 간단하게 이미지 분류 문제를 해결할 수 있지만, 시간복잡도, 메모리복잡도의 문제가 발생한다.
- 이런 문제를 해결할 수 있는 게 Neural Network 개념이다.

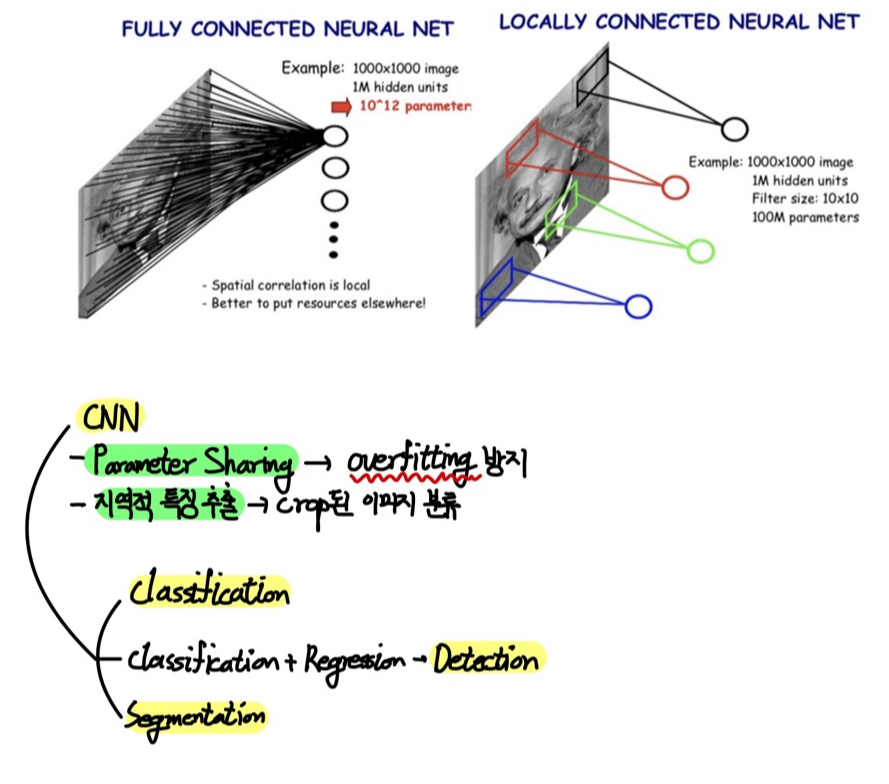
Single-layer Neural Network(Fully Connected Neural Net)
- input 이미지의 모든 픽셀에 서로 다른 가중치 내적을 적용한 후 bias를 더한 sum을 non-linear Activation Function에 통과시키는 방법이다.
- crop된 이미지를 분류하지 못한다.

Convolution Neural Network(Locally Connected Neural Network)
- fully connected neural network와 달리 국부적인 영역의 특징 추출
- parameter sharing으로 parameter의 수를 획기적으로 감소시킴 -> overfitting 방지
- crop된 이미지 분류 가능
CNN기반 Image Classification의 역사
- CNN 구조는 1998년 Yann Lecun에 의해 처음 제안되었으나, 2012년 AlexNet의 등장 이후부터 각광받기 시작했다.

AlexNet
- 5개의 Convolution Layer, Fully Connected Layer 3개로 이루어짐
- 활성화 함수로 relu와 max pooling을 사용
- 활성화 함수로 ReLU를 사용하기 때문에, conv나 pooling 시에 매우 높은 픽셀 값이 주변에 영향을 주기 쉽기 때문에 LRN(Local Response Normalization)을 사용한다.

Relu 함수
- 양수는 그대로, 음수는 0으로 반환하기 때문에, 특정 양수 값에 수렴하지 않는다.
- 출력값의 범위가 넓고, 양수인 경우 자기 자신을 그대로 반환하기 때문에, 심층 신경에서 시그모이드 함수를 활성화 함수로 사용했을 때 발생한 문제였던 Vanishing Gradient(기울기 소실) 문제가 발생하지 않는다.
- 단순한 형태를 가지기 때문에, 경사 하강 시에 다른 활성화 함수에 비해 학습 속도가 매우 빠르다. (SGD의 경우 시그모이드, 하이퍼볼릭 탄젠트 함수에 비해 수렴 속도가 약 6배 빠르다.)
- ReLU는 편미분(기울기) 시에 1로 일정하므로, 가중치 업데이트가 속도가 매우 빠르다.
import matplotlib.pyplot as plt
import numpy as np
def ReLU(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = ReLU(x)
fig = plt.figure(figsize=(8,6))
fig.set_facecolor('white')
plt.title("ReLU", fontsize=30)
plt.xlabel('x', fontsize=15)
plt.ylabel('y', fontsize=15, rotation=0)
plt.axvline(0.0, color='gray', linestyle='--', alpha=0.8)
plt.axhline(0.0, color='gray', linestyle='--', alpha=0.8)
plt.plot(x,y)
plt.show()
- 가중치가 업데이트되는 과정에서 가중치 합이 음수가 되는 순간 ReLU는 0을 반환하기 때문에 해당 뉴런은 그 이후로 0만 반환하는 아무것도 변하지 않는 현상이 발생할 수 있으며, 이를 Dying ReLU 현상이라고 한다.
VGG
- AlexNet과 형태가 유사하나, layer가 더 깊어졌다.
- LRN을 사용하지 않고, 보다 작은 필터를 사용한다.
- 미리 학습된 특징들을 다른 task에 활용할 수 있을 정도로 개선된 일반화 성능을 보였다.

Problems with Deeper Layers
- AlexNet에서 VGG로 넘어가면서 Layer가 깊을 수록 성능이 무조건 좋아진다고 인식할 수 있지만, 그렇지 않다.
- 단순히 네트워크를 깊게 쌓으면 최적화하기 어렵다는 문제가 발생한다.
- 깊은 네트워크에서 역전파 알고리즘을 수행할 경우에, Gradient 값이 너무 커지거나(Exploding), 소실에 가까울 정도로 너무 작아진다(Vanishing).
- 추가적으로 계산복잡도가 증가하여 하드웨어 요구사항이 까다로워지는 문제가 있다.
GoogLeNet
- 층이 깊어질 때 발생하는 문제를 해결하기 위해, Inception module이라는 새로운 구조 제안
- 하나의 층에서 다양한 사이즈의 필터를 활용, 이후 각 필터를 거친 출력 값을 channel 축으로 concat
ResNet
- 100개 이상의 깊은 층을 갖는 구조를 가지고 ImageNet에서 최초로 인간보다 뛰어난 성능을 달성하며, 더 깊은 층을 쌓을수록 성능이 좋아진다는 것을 보여준 첫 논문
DenseNet
- Residual block에서는 skip connection을 통해 identity mapping을 구현했지만, Dense block에서는 채널 축을 중심으로 concatenation을 수행하도록 되어있음
SENet
- depth를 높히거나 connection을 추가해주는 것이 아닌, 채널 축을 중심으로 feature map에 대한 attention을 계산함으로써 각 채널 간의 관계를 모델링하고 중요한 특징에 보다 큰 가중치를 부여할 수 있도록 설계되었다.
EfficientNet
- width scaling, depth scaling, resolution scaling의 세 가지 방식을 적절하게 활용하여 훨씬 좋은 성능을 달성하는 것을 목표로 제안된 EfficientNet의 compound scaling
Deformable Convolution
- 일반적인 convolution이 아닌 불규칙적인 convolution을 수행하는 방법
- 모든 구성요소의 위치가 정해져있는 자동차, 서랍장 등과 다르게 동물이나 사람 등의 경우 그 움직임에 따라 각 구성요소들의 상대적 위치가 달라질 수 있다.
참고자료
컴퓨터 비전의 모든 것
부스트코스 무료 강의
www.boostcourse.org
[머신러닝] 딥러닝의 시작 Neural Network 정복하기 1
시작하며 우리는 저번 포스팅에서 Overfitting을 다루며 배웠던 'non-linear classification' 에서, feature가 두개일 때 위와 같이 Decision Boundary를 표현해보았습니다.. Overfitting https://box-world.tistory.com/16?categor
box-world.tistory.com
CNN의 등장과 발전 과정 - 1 (LeNet, AlexNet, GoogleNet)
📌CNN의 등장 CNN은 데이비드 허블(David H. Hubel / 캐나다 신경학자)과 토르스텐 비셀(Torsten Wiesel / 스웨덴 신경학자) 이 두 신경학자는 1959년에 시각피질 구조에 대한 실험을 수행했다. 실험에서는
dotiromoook.tistory.com
딥러닝-3.4. 활성화함수(5)-렐루 함수(ReLU)
지금까지 계단 함수, 선형 함수, 시그모이드 함수, 소프트맥스 함수, 하이퍼볼릭 탄젠트 함수에 대해 다뤄보았다. 이들은 은닉층에서 사용해서는 안되거나, 사용할 수 있더라도 제한적으로 사용
gooopy.tistory.com
LRN(Local Response Normalization) 이란 무엇인가?(feat. AlexNet)
LRN(Local Response Normalization) LRN(Local Response Normalization)은 현재는 많이 사용되지 않습니다. 그러나 Image Net에서 최초의 CNN우승 모델인 AlexNet에서 사용했으며 작동방식에 대해 알아보도록 하겠습니다.
taeguu.tistory.com
'KHUDA 4th > Computer Vision' 카테고리의 다른 글
| [네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(2) (0) | 2023.09.27 |
|---|---|
| [네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(1) (0) | 2023.09.26 |
| Convolution Neural Network(합성곱 신경망) (0) | 2023.09.24 |
| [네이버 부스트 코스] 2. 데이터 부족 문제 완화 (0) | 2023.09.20 |
| [KHUDA 4th] CV 1주차 OT (09.13) (1) | 2023.09.16 |



