
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 회귀
- LG
- PCA
- gpt
- ChatGPT
- Classification
- 머신러닝
- OpenAI
- 분류
- LG Aimers
- supervised learning
- deep learning
- regression
- AI
- 오블완
- LLM
- Machine Learning
- 티스토리챌린지
- GPT-4
- 지도학습
- 해커톤
- LG Aimers 4th
- 딥러닝
- Today
- Total
SYDev
[네이버 부스트 코스] 4. CNN Visualization 본문
본 게시물은 네이버 부스트 캠프 cv 강의(https://www.boostcourse.org/ai340/joinLectures/369545)를 기반으로 작성된 게시물입니다.
CNN Visualization의 개념 및 활용목적을 파악하고,
어떤 방식으로 시각화를 진행하는지에 대해 알아보자.
What's CNN Visualization?
- CNN Visualization: CNN 내부를 시각화하여, 모델의 학습 과정을 직관적으로 확인할 수 있도록 하는 과정
- 직관적으로 파악이 어려운 Black Box 형태의 CNN 내부를 시각화하여, 모델이 어떤 학습 과정을 거쳐 성능을 잘 내는지와 어떻게 모델 성능을 향상시킬 수 있는지 생각해볼 수 있다.

기본적인 예시: Filter Visualization

- Convolution의 역연산인 Deconvolution을 통해서 모델의 학습과정을 시각화
- Deconvolution: input pixel 주위에 zero-padding을 추가한 뒤 convolution 연산을 진행하여, output size를 input size와 같게 만든다.
- 낮은 계층 -> 구체적인 방향성에 대한 정보를 담고있는 필터
- 높은 계층 -> 추상적이고 의미론적인 정보를 담고있는 필터

-> filter weight visualization -> 컬러 디텍터, 각도 디텍터, 블록 디텍터 등 기본적인 operation을 학습한 필터 -> 이에 activation을 취한 결과 visualization -> 45도 대각에 대한 성분을 강하게 검출
->> 간단한 시각화를 통해 CNN 내부 필터가 어떤 정보에 집중하고 있는지 직관적으로 확인
Neural Network를 시각화하는 방법
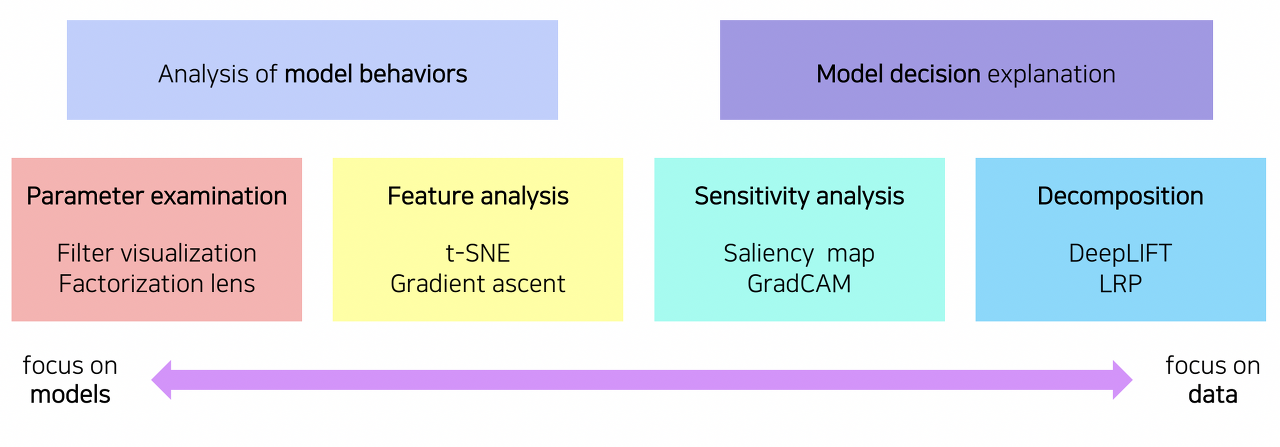
-> neural network를 시각화하는 방법은 크게 모델의 행동, 동작 방식을 분석하는 방법과 모델의 예측 결과를 설명하는 방법으로 분류할 수 있다.
Analysis of Model Behaviors
Embedding Feature Analysis
- Query Images를 입력으로 받았을 때, DB 내에서 입력 이미지와 비슷한 이미지를 보임으로써 시각화를 구현 -> 비슷한 이미지들이 클러스터링되어있는지 판단!!
- Nearest-Neighbor 방식 활용
- DB에 저장된 이미지를 학습된 네트워크에 foward pass 시킴으로써 feature를 embedding vector로 표현하고, 해당 features를 고차원 공간에 저장한다. 이후 Query Image 또한 같은 방식으로 embedding vector로 변경하여 NN 방식을 이용해 거리가 가까운 image의 embedding vector를 나열한다.
- 시각화를 위해서 고차원 feature 공간을 저차원으로 바꾸는 Dimentionality Reduction 과정이 필요하다. 대표적으로 t-SNE 방법이 있다.

t-SNE
>> 추후 기입
Activation Investigation
Middle, High layer를 해석하는 방법
Layer Activation

- 특정 채널의 hidden node 적절한 activation 값으로 thresholding(binary image로 표현)하여 mask를 만들고, 이를 원본 이미지에 씌우면 위 그림과 같은 결과를 얻을 수 있다.
- 모델이 사람의 얼굴과 계단 객체를 인식하고 이외에도 여러 요소들을 복합적으로 연결하여 학습한다는 것을 파악할 수 있다.
Maximally Activating Patches

- CNN의 각 층에서 가장 높은 activation 값을 가지는 hidden node의 patch를 확인하여, 해당 node에서 무슨 역할을 하고 있는지 시각화
- 국부적인 patch를 보므로, middle level의 분석에 용이하다.
구현 과정
1. CNN의 특정 layer에서 channel 하나를 고른다.
2. 예제 데이터를 backbone network에 넣어서, 각 layer의 activation을 모두 얻어내고 1.에서 고른 channel의 activation map을 저장한다.
3. 저장된 채널의 activation값 중에서 가장 큰 값을 갖는 위치를 파악하고, 해당 위치의 receptive field를 찾아낸다.
4. 해당 receptive field에 대한 입력 영상의 해당 patch를 얻는다.
Class Visualization

- 데이터를 사용하지 않고, 네트워크에 내재된 정보를 시각화하는 방법
- 위 그림에서 알 수 있듯이, 클래스가 '새'만을 포함한 것이 아닌, 주변 나뭇가지와 같은 이미지를 같이 포함하고 있다.
- 아래의 이미지도 마찬가지로 '개'만을 포함한 것이 아닌, 주변의 아이까지 포함하고 있어 '개'에 가족적인 이미지까지 더해 학습하고 있다고 추측할 수 있다.

- $I:$ 영상 입력
- $f(I):$ 입력이 CNN을 거쳐 나온 class score
임의의 argmax 결과를 사용하다 보면, 추상적인 값이 공교롭게도 가장 큰 값일 때가 있다. 이를 이해할 수 있는 형태로 바꿔주기 위해서 간단한 loss인 정규화 term을 추가한다.
Loss를 최대화하는 gradient descent와 달리, $f(I)$가 최대화되도록 해야하므로 gradient ascent를 사용한다.
Gradient Ascent 과정
1. 임의의 영상(blank/monotone/noisy image 등 여러 종류 선택 가능)을 CNN에 넣어 타겟 클래스의 prediction score를 얻는다.
2. Back propagation으로 입력 image의 gradient(target score가 높아지는 방향으로)를 찾는다.
3. Target score가 높아지는 방향으로 input image를 update한다.
4. 업데이트된 영상을 input으로 1-3 과정을 반복한다.
Model Decision Explanation
Saliency Test
이미지가 주어졌을 때, 그 이미지가 올바르게 분류되기 위한 각 영역의 중요도를 추출하는 방법이다.
Occlusion map

- input image에서 특정 영역을 occlusion patch로 가려 score를 계산하여, 어느 영역이 중요한지 파악한다.
- 모든 영역에 대해서 occlusion을 수행한 후에, 그 스코어를 맵으로 나타낸 것이 occlusion map이다.
via Backpropagation

- 특정 이미지를 분류하고, 그 예측 결과에 결정적으로 영향을 미친 부분이 어디인지 heatmap으로 시각화하는 방법
- 관심 물체 영역에 밝은 값들이 분포
via Backpropagation 구현 과정
1. input 영상을 넣어주고, 하나의 class score를 얻는다.
2. Backpropagation을 입력 도메인까지 진행한다.
3. 2. 과정을 통해 얻는 gradient에 절대값 혹은 제곱을 취해준다.
4. 3. 과정을 통해 얻은 gradient를 gradient magnitude map을 통해서 시각화한다.
Backpropagation-based Saliency
Deconvnet

- 일반적인 CNN의 foward 과정에서는 activation function으로 relu가 사용되어, 음수가 0으로 마스킹된다.
- backpropagation 과정에서는 현재 값들이 아닌 foward시에 0 이하였던 unit들을 기준으로 음수 마스킹한다.
- Deconvnet 연산에서는 Backpropagation 시점을 기준으로 음수를 마스킹한다.
Guided Backpropagation

- forward pass를 통해 얻은 mask와 deconvolution을 통해 얻은 mask를 AND gate를 활용하여 union시키고, 이를 하나의 mask로 backpropagation 수행

Class Activation Mapping
class activation mapping(CAM)

- 기본 CNN의 구조에서 input image가 주어졌을 때, conv layers를 모두 통과하고 fc layer를 통과하기 전, Global Average Pooling을 진행하여 얻어진 GAP features를 얻는다.
- 이렇게 구한 GAP features에 가중치를 곱하여 모두 더함으로써 class의 score를 얻을 수 있는데, 이 과정에서 수식의 변형을 통해 CAM을 구할 수 있다.
- CAM은 GAP를 적용하기 이전의 값이기 때문에 공간정보가 남아있다고 볼 수 있고, 이런 CAM을 시각화하면 아래와 같은 결과가 나타난다.
- 이처럼 물체의 위치 파악과 같이 정교한 task를 image classification과 같은 rough한 task로 간접적으로 학습시키는 방식을 weakly-supervised learning이라 한다.

- 다만, CAM 적용을 위해서는 마지막 부분을 GAP, FC layer로 바꿔서 재학습시켜야 해서, 원래 모델보다 성능이 떨어질 수 있다는 한계점이 있다.
Grad-CAM
- 구조를 변경하지 않고 pretrained 모델에서 CAM을 뽑을 수 있는 방식
- 기존 모델 구조를 바꿀 필요가 없기 때문에 영상 인식에 국한될 필요 없이, backbone이 CNN이기만 하면 사용할 수 있다.

Importance Weight of the k-th feature map with respect to the class c
>> Saliency를 backpropagation으로 구했던 방법 응용
1. 기존의 Saliency test의 경우와 달리, 입력까지가 아닌 원하는 activation layer까지만 backpropagation을 수행한다.
2. 클래스 c에 대한 정답 레이블 y를 변화시키는 loss로부터 backpropagation loss를 구한다.
3. 공간 축으로 GAP를 수행하여 각 채널의 gradient 성분의 크기(α)를 계산한다. -> 이것이 weight
4. 새로 구한 weight와 activation map을 선형결합하여 ReLU를 적용하여 히트맵으로 표현하면 Grad-CAM이 된다.
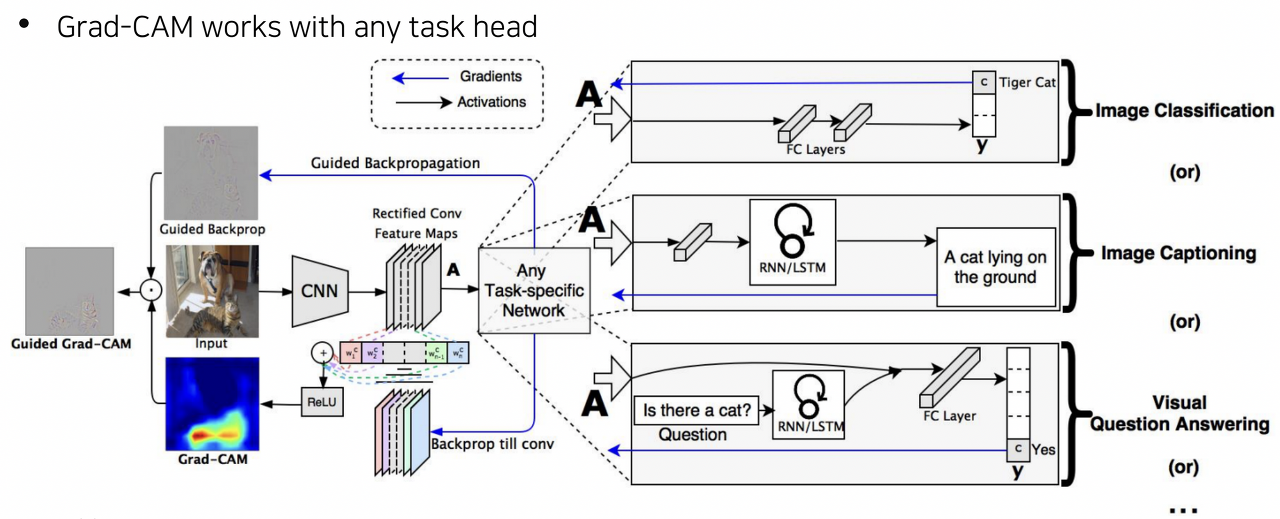
>> Grad-CAM은 뒤에 어떤 구조가 오더라도 사용 가능!!
Scouter

- 모델이 왜 해당 결과로 예측한 것인지에 대하여 시각화하는 방법이 Grad-CAM이라면, 모델이 왜 다른 결과로 예측하지 않았는지에 대하여 시각화하는 SCOUTER라는 방법도 제안되었다.
참고자료
컴퓨터 비전의 모든 것
부스트코스 무료 강의
www.boostcourse.org
Deconvolution 이란 무엇인가?
Deconvolution CNN에서 convolution layer는 convolution을 통해서 feature map의 크기를 줄인다. 하지만 Deconvolution은 이와 반대로 feature map의 크기를 증가시키는 방식으로 동작한다. Deconvolution은 아래와 같은 방
3months.tistory.com
Computer Vision 05 - CNN 시각화(Visualization)
Semantic segmentation by 오태현 교수님, BoostCamp AI Tech 7주차
blogik.netlify.app
'KHUDA 4th > Computer Vision' 카테고리의 다른 글
| [네이버 부스트 코스] 5. Advanced Models(1) (0) | 2023.10.30 |
|---|---|
| [KHUDA 4th] CV 5주차 세션 (10.11) (0) | 2023.10.12 |
| [KHUDA 4th] CV 4주차 세션 (10.04) (1) | 2023.10.05 |
| [KHUDA 4th] CV 2주차 세션 (09.27) (0) | 2023.09.28 |
| [네이버 부스트 코스] 3. Sementic Segmentation & Object Detection(2) (0) | 2023.09.27 |



