
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 딥러닝
- 해커톤
- LG Aimers
- 회귀
- 오블완
- Machine Learning
- Classification
- regression
- deep learning
- LG Aimers 4th
- LG
- LLM
- OpenAI
- GPT-4
- ChatGPT
- gpt
- 티스토리챌린지
- 지도학습
- 분류
- 머신러닝
- PCA
- AI
- supervised learning
- Today
- Total
SYDev
[KHUDA 4th] CV 5주차 세션 (10.11) 본문
오늘은 further questions와 실습 코드에 대해서만 다룰 예정
Further Questions
Q1. 왜 filter visualization에서 주로 첫번째 convolutional layer를 목표로 할까?
CNN filter는 첫번째 convolutional layer의 input이 RGB 채널로 이루어져 있어 직관적으로 이해하기가 쉽다. 반면에 뒤로갈수록 인간이 직관적으로 이해하기가 어렵다는 특징이 있다.
Q2. Occlusion map에서 heatmap이 의미하는 바가 무엇인가?
각 픽셀이 얼마만큼의 중요도를 갖는지 나타내는 score라 해석할 수 있다. 확률값으로 계산하므로 heatmap으로 시각화할 수 있다.
Q3. Grad-CAM에서 linear combination의 결과를 ReLU layer를 거치는 이유가 무엇일까?
오직 관심 있는 class에 positive 영향을 주는 feature에만 관심이 있기 때문이다. 이를 위해서 ReLU Layer를 거쳐 양수만 남긴다. ReLU를 적용하지 않으면, localization에서 더 나쁜 성능을 보인다.
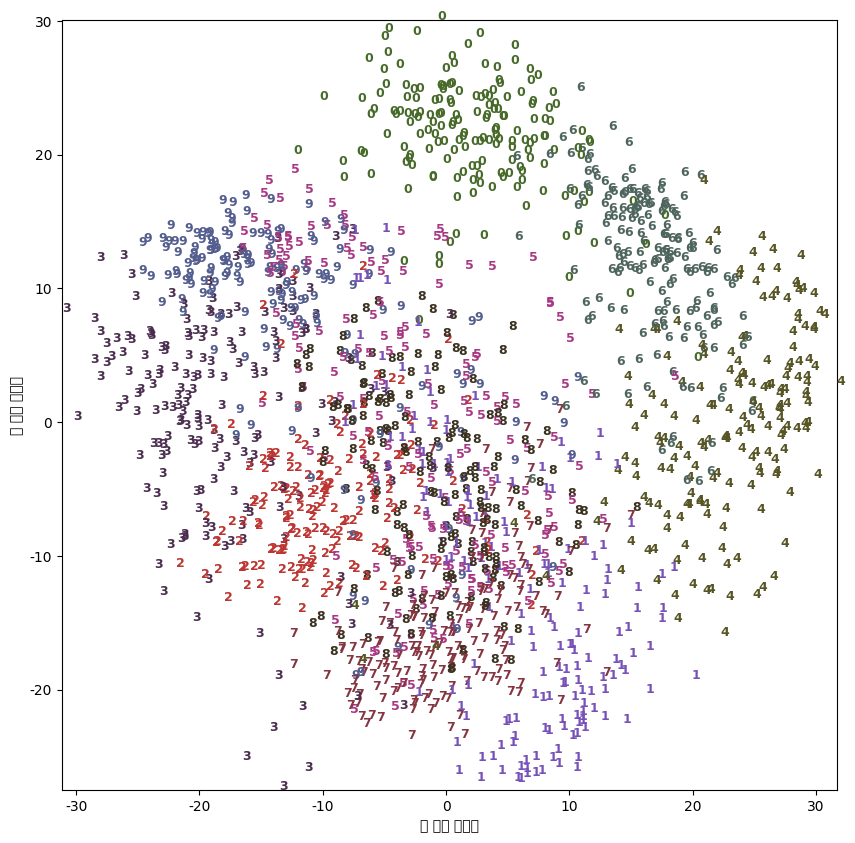
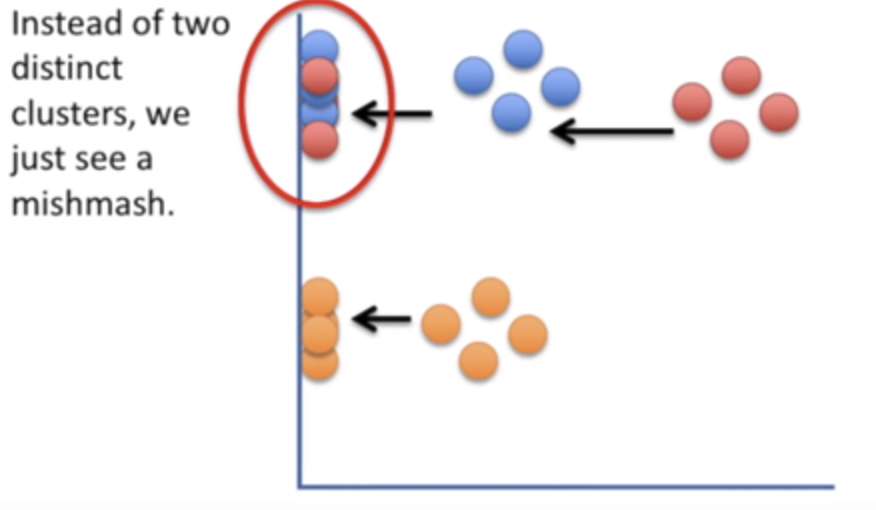
실습1. PCA vs. t-SNE

PCA
선형 방식으로 정사영하여 차원 축소를 진행하기 때문에 클러스터링이 무너지기 쉽다.
t-SNE

결론
>> t-SNE는 t 분포를 사용함으로써 crowding proplem을 해결했으므로, visualization했을 때 PCA보다 clustering이 잘 보존된다!!
실습2.
실습2는 해당 블로그 코드를 가지고 진행됨 >> https://junstar92.tistory.com/152
# 이미지를 정규화 하세요 (픽셀값: 0~255)
image = image / 255.0
# 이미지를 224 x 224 사이즈로 Resize 하세요
image = tf.image.resize(image, (224, 224))-> 0~255의 픽셀값을 0~1로 정규화하려면 255.0로 나누면 간단함
# add a GAP layer
output = tf.keras.layers.GlobalAveragePooling2D()(base_model.output)
# output has two neurons for the 2 classes(dogs and cats), Use softmax
output = tf.keras.layers.Dense(2, activation='softmax')(output)-> 2진분류하도록 설정
# Class Activation Mapping을 통해 Class Activation Map을 구하여라 (Hint: Use np.dot, class_activation_weights, class_acitvation_features)
cam_output = np.dot(class_activation_features, class_activation_weigths)-> class activation features와 weights 내적
참고자료
CNN visualization
Week7(CV), Day 33. CNN Visualization
velog.io
[ML with Python] 3.비지도 학습 알고리즘 (2-3) t-SNE Manifold
[ML with Python] 3. 비지도 학습 알고리즘 (2-3) (T-SNE) Manifold Learning 본 포스팅은 Manifold Learning에 관한 기본적인 내용에 관하여 다룹니다. 확률적 임베딩(SNE) t-분포 확률적 임베딩(t-SNE)
jhryu1208.github.io
차원 축소 알고리즘을 비교해보자 (PCA, T-sne, UMAP)
차원 축소 알고리즘들은 축소하는 방법에 의해 두 가지로 나눌 수 있음matrix factorization 계열 - pcaneighbour graphs - t-sne, umapmatrix factorization 을 base 로 함 (공분산 행렬에 대해서 svd 등)분산
velog.io
'KHUDA 4th > Computer Vision' 카테고리의 다른 글
| [네이버 부스트 코스] 5. Advanced Models(2) (0) | 2023.10.30 |
|---|---|
| [네이버 부스트 코스] 5. Advanced Models(1) (0) | 2023.10.30 |
| [네이버 부스트 코스] 4. CNN Visualization (1) | 2023.10.08 |
| [KHUDA 4th] CV 4주차 세션 (10.04) (1) | 2023.10.05 |
| [KHUDA 4th] CV 2주차 세션 (09.27) (0) | 2023.09.28 |



