
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- ChatGPT
- 분류
- 딥러닝
- gpt
- 티스토리챌린지
- 회귀
- LG
- LG Aimers 4th
- AI
- 오블완
- Machine Learning
- deep learning
- 해커톤
- PCA
- GPT-4
- 지도학습
- 머신러닝
- LG Aimers
- supervised learning
- OpenAI
- Classification
- regression
- LLM
- Today
- Total
SYDev
[네이버 부스트 코스] 5. Advanced Models(1) 본문
본 게시물은 네이버 부스트 캠프 cv 강의(https://www.boostcourse.org/ai340/joinLectures/369545)를 기반으로 작성된 게시물입니다.
Computer Vision 분야에서 사용되는 여러가지 모델들에 대해서 알아보자.
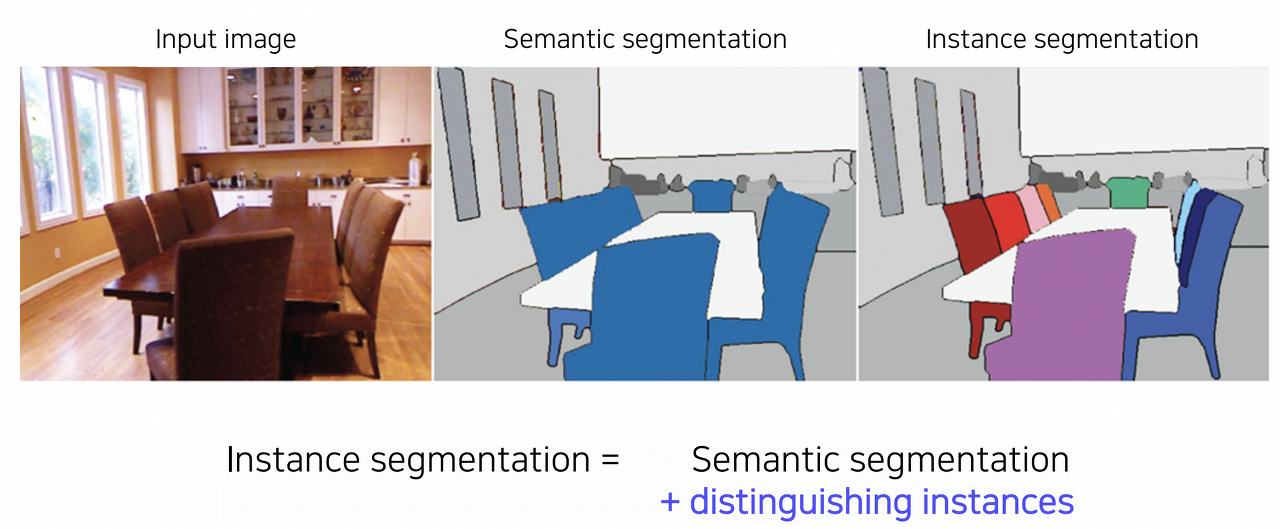
Instance Segmentation
- Image Segmentation: Image classification의 확장으로, 이미지 내 정보의 분류와 이미지 속 픽셀 수준에 무엇이 있는지 이해하는 데에 사용하는 컴퓨터 비전 기술이다.
- semantic segmentation + distinguishing instances
Mask R-CNN

- 기존의 Faster R-CNN에서는 RPN의 region proposal을 기반으로 ROI polling 기법을 사용했기 때문에 정수 좌표만 다뤘으나, Mask R-CNN에서는 ROIAlign이라는 새로운 pooling layer를 사용하여 interpolation(이미 알려진 값 사이에 위치한 값을 알려진 값을 기반으로 추측)을 기반으로 소수점 픽셀 수준에서의 pooling을 지원한다.

YOLACT
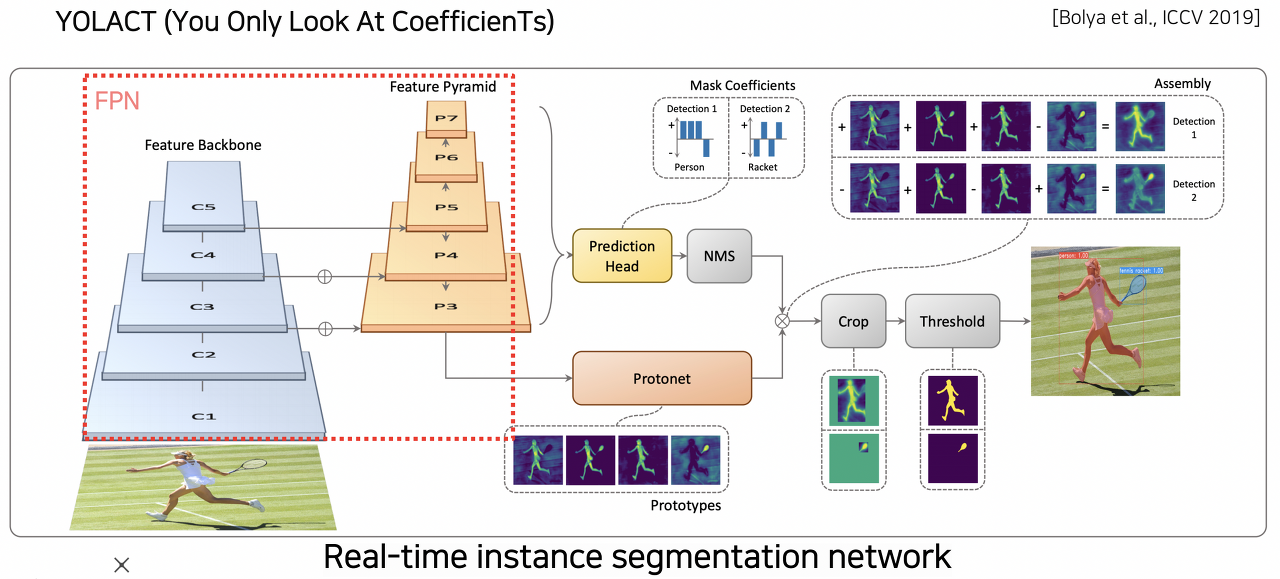
- mask R-CNN는 two-stage 모델로, feature localization 과정에 많은 신경을 쓴다. 하지만 이렇게 localization 이후 mask를 순차적으로 예측하는 과정은 속도를 올리기에 한계가 있다.
- YOLACT는 mask R-CNN과 달리 single-stage 구조이다.
- feature pyramid 기반의 구조를 기반으로 하여 고해상도의 featue map 활용 가능
- mask의 프로토타입 추출해서 사용 -> mask를 합성해낼 수 있는 soft segmentation component(선형대수 관점의 basis)
- 마지막으로 prediction head에서 프로토타입을 잘 합성하기 위한 계수(mask coefficients) 출력 -> 이를 프로토타입과 선형 결합하여 최종적으로 response map 생성
YolactEdge

- Yolact는 소형의 edge device에서 사용할만큼 빠르진 않다.
- 이런 edge device에서 사용가능한 수준으로 제안된 것이 YolactEdge 모델이다.
- 이전 frame 중에서 key frame에 해당하는 feature를 다음 frame으로 전달하여 feature map에 대한 계산량을 획기적으로 줄임
Panoptic Segmentation
- instance segmentation는 작은 물체에 대한 구분에서 유리하지만, 배경을 인식해야 하는 task에서는 semantic segmentation이 유리
- Panoptic Segmentation: 물체를 개별로 구분하고 배경까지 인식하는 task
UPSNet (A Unified Panoptic Segmantation Network)

- FPN을 backbone network로 활용
- head branch를 semantic head, instance head 둘로 나눈다.
- 마지막으로 각 헤드의 출력을 취합하여 panoptic head에 입력해 panoptic segmentation map을 구한다.

- 각 헤드에서 나온 결과는 각 instance에 해당하는 mask, 물체와 배경을 예측하는 mask들이 있다.
- 배경에 해당하는 mask는 즉시 최종 출력에 넣는다.
- semantic head의 물체 부분을 masking하여 instance 부분과 합한 결과를 최종 출력에 넣는다.
- instance와 배경에 관련된 클래스 이외에 unknown 클래스를 별도로 처리한다.
- 물체의 semantic mask map에 instance로 사용된 부분을 제외한 부분을 모두 unknown 클래스로 처리하여 최종 출력에 넣는다.
VPSNet

- panoptic segmentation 구조를 video로 확장
- 시간 차를 가지는 두 프레임 사이에 ϕ라는 motion map을 먼저 사용해서 각 프레임에서 출력된 feature map을 motion에 따라 warping
- motion map은 한 프레임에서 다른 프레임의 변화에서 각 점이 다음 프레임에서 어떤 점으로 매핑되는지, 그 대응 관계를 가지고 있는 모션을 나타낸 맵
- t - τ 프레임의 feature map을 motion map을 통해 마치 t 프레임의 feature map처럼 만들어주는 것
- target frame의 feature map과 warping된 feature map를 합쳐서 사용
- 여러 프레임의 feature map을 활용하면서 연속적인 시간에서 스무스한 segmentation map을 얻음

- ROI의 featue를 추출하고, 이를 tracking head에 활용함으로써 기존의 ROI와 current ROI들이 어떻게 서로 연관되어 있는지 그 전에 몇 번 ID를 가졌던 물체였는지 파악하고 matching
- 이를 통해서 물체는 시간이 지나도 같은 ID를 가질 수 있도록 tracking

- Bounding box head, mask head, semantic head, tracking head의 출력을 기반으로 하나의 panoptic segmentation map을 출력
Landmark Localization
- Landmark Localization: 특정 물체에 대해서 중요하다고 생각되는 부분들을 landmark로 정의하고, 이 landmark들을 추정하고 tracking하는 task, 사람의 얼굴이나 포즈 등을 추정하고 tracking하는 분야에 주로 활용
- 예를 들어 facial landmark라고 하면 입꼬리나 입 중간 지정 등 얼굴 구조를 파악하는데 필요한 기본적인 point들의 구성이다.
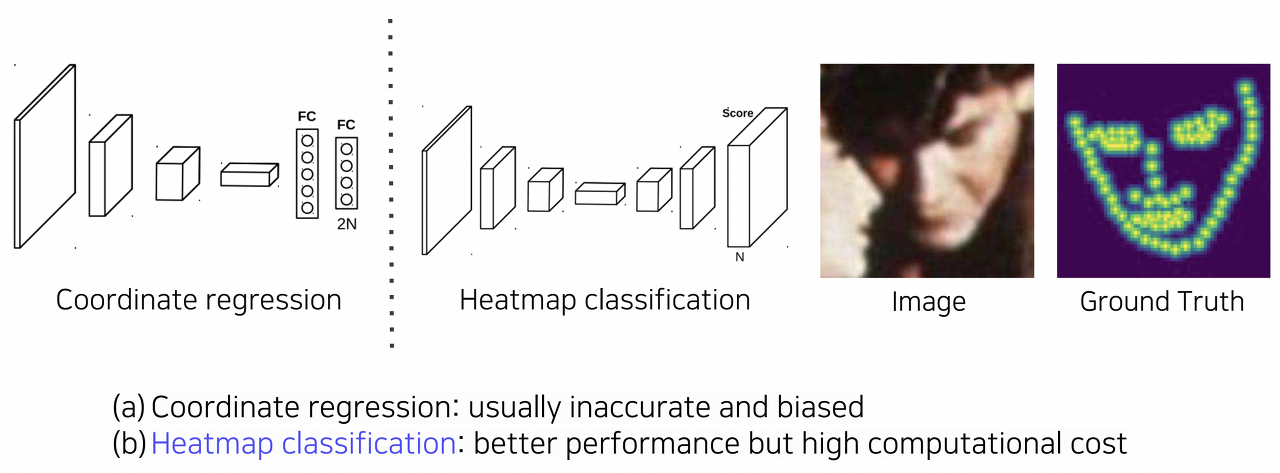
- Landmark localization을 해결하는 대표적 방법으로 regression과 heatmap이 있다.
- regression 방법은 대게 부정확하고 biased되어 있다.
- 그 대안으로 heatmap classification 방법이 있는데, 이는 각 채널들이 하나의 key point를 담다하여 key point마다 하나의 클래스처럼 고려하여 그 key point가 발생할 확률을 각 픽셀마다 구하여 classification을 수행하는 방법이다. -> 모든 픽셀에 대해 연산을 수행하는 만큼 계산량이 크다.

Hourglass Network

- heatmap classfication을 잘 활용하기 위해 제안된 구조
- U-Net처럼 넓은 receptive field를 확보하기 위해 downsampling과 upsampling 과정을 거치는 블럭들이 반복적으로 이어진 구조 -> 해당 구조가 마치 모래시계와 닮았다 하여 stacked hourglass module이라 부른다.
- 해당 구조에서도 skip connection을 통해 upsampling 과정에서 low-level feature를 잘 고려할 수 있도록 설계됨
- U-Net과 달리 low-level feature map을 바로 사용하지 않고 별도의 con layer를 통과시켜 사용, concatenation이 아닌 합하는 방식으로 사용(what is diff between concat and add? -> https://masterzone.tistory.com/36)
- add -> 픽셀 단위로 모두 더해서 두 개의 featue map을 하나의 feature map으로 합치는 연산
- concat -> 두 개의 featue map을 2차원으로 쌓은 feature map 한 개로 합치는 연산 (두 개의 feature map 보존)

- 이런 블럭을 여러 개 쌓아 결과를 반복적으로 개선
DensePose

- 신체 전체의 landmark를 파악하는 task -> 이미지의 3D 정보를 파악
- UV map으로 표현

- UV map은 표준 3D 모델을 U축과 V축으로 이루어진 2D 형태로 펼친 좌표 표기법이다.
- UV map의 한 점은 3D mesh(점 -> 다각형 -> mesh) 상의 한 점과 일치하도록 표현
- UV map 상의 좌표를 알고 있으면 이를 바로 3D mesh의 형태로 표현 가능, 좌표의 값이 변해도 UV map과 3D mesh의 mapping 관계는 변하지 않는다.

- DensePose는 faster R-CNN의 구조에 3D surface regression branch를 더하여 이를 통해 최종 UV map을 출력
RetinaFace
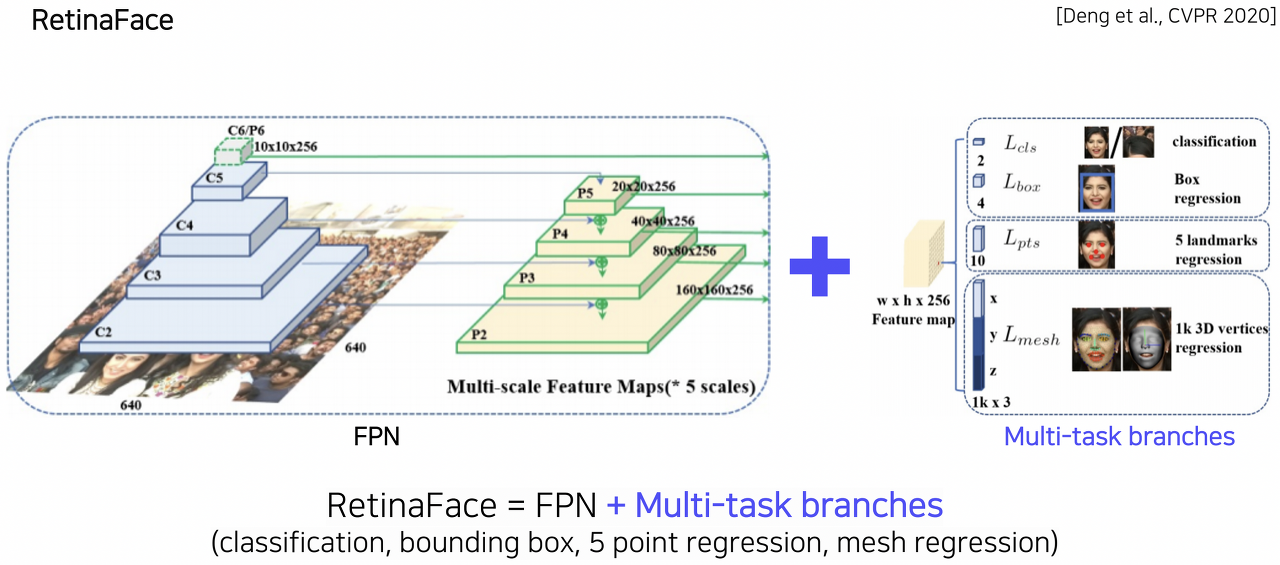
- 기본적인 FPN을 backbone으로 가지고, task에 따라 세부적으로 head만 추가/변경하는 형태로 응용
- 다양한 방식을 브랜치를 통해 한 번에 수행하돌고 하는 구조를 multi-task branch라 부른다.
- multi-task 형태로 학습을 수행하면 backbone network가 보다 robust(이상값에 영향을 덜 받음)하게 학습된다.
Detecting Objects as Keypoints
CornerNet
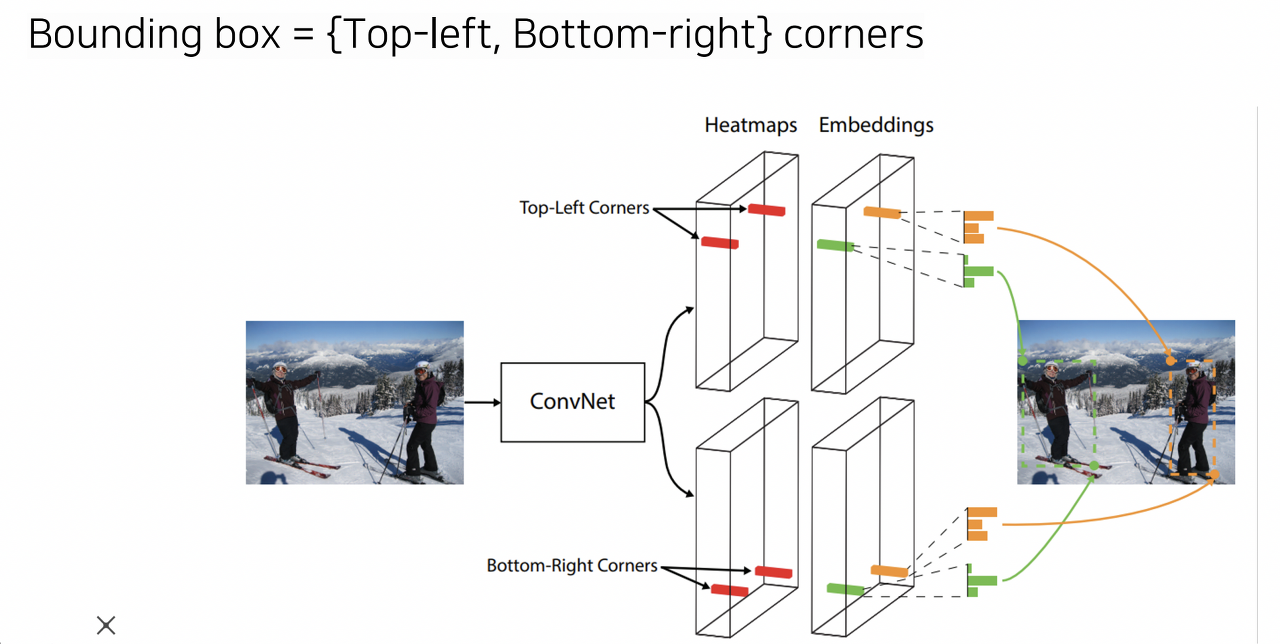
- 좌상단의 좌표, 우하단의 좌표 두 개의 코너를 활용하여 unique하게 bounding box를 결정한다.
- backbone network의 feature map을 좌상단 좌표를 구하는 branch와 우하단의 좌표를 구하는 branch로 나누어 입력하고, 각각의 branch에서 같은 object로부터 나온 코너라면 embedding이 동일한 클래스로 mapping되어야 한다는 것을 목적으로 학습
- single-stage 구조에 가깝기 때문에 성능보다는 속도에 집중한 구조
CenterNet

- 성능이 아쉬웠던 cornernet의 단점을 극복하고자 좌상단, 우하단의 코너뿐만 아니라 센터의 좌표까지 box를 정의하는 요소로 사용

- centernet의 variation으로 너비와 높이, 센터 포인트의 좌표로 bounding box를 결정하는 방법

>> 이전 모델들과 비교했을 때, 준수한 성능을 보이며 성능 대비 속도도 가장 빠르다.
참고자료
Image Segmentation 이란? - 정의, 종류, 응용분야, 딥러닝, 트렌드
Image segmentation은 이미지 내 정보를 분류할 뿐만 아니라 픽셀 수준에서 무엇이 있는지 이해하는 것입니다. image segmentation 모델은 개별 object detection부터 이미지 속 여러 영역에 개별 레이블을 지정
www.thedatahunt.com
Mask R-CNN 논문(Mask R-CNN) 리뷰
이번 포스팅에서는 Mask R-CNN 논문(Mask R-CNN)을 읽고 리뷰해보도록 하겠습니다. Mask R-CNN은 일반적으로detection task보다는 instance segmentation task에서 주로 사용됩니다. Segmentation 논문을 읽어본 경험이
herbwood.tistory.com
논문 리뷰 - YOLACT: Real-time Instance Segmentation
Instance segmentation 문제를 real-time으로 해결할 수 없을까? 라는 의문으로 시작이 된다. 여태까지의 instance segmentation 모델은 잘 만들어진 object detection에 병렬적으로 모델을 추가하여 (e.g., mask R-CNN(Fas
byeongjokim.github.io
[시각지능] Landmark localization
Landmark localization은 facial keypoint나 human pose에서의 skeleton을 구성하는 기본적인 요소인 anchor point들을 찾는 task이다. 이를 위해서 landmark라는 단어의 정의가 먼저 필요하다. Facial lan
velog.io
3D 그래픽의 이해 : 용어정리 - 매시(Mesh), 폴리곤(Polygon), 버텍스(Vertex)
실세계에서 3차원 공간의 객체를 바라볼 때 우리는 그 객체의 외관 또는 겉모습만을 볼 수 있다.&nb...
blog.naver.com
'KHUDA 4th > Computer Vision' 카테고리의 다른 글
| [네이버 부스트 코스] All of Computer Vision 수료 완료 (0) | 2023.11.01 |
|---|---|
| [네이버 부스트 코스] 5. Advanced Models(2) (0) | 2023.10.30 |
| [KHUDA 4th] CV 5주차 세션 (10.11) (0) | 2023.10.12 |
| [네이버 부스트 코스] 4. CNN Visualization (1) | 2023.10.08 |
| [KHUDA 4th] CV 4주차 세션 (10.04) (1) | 2023.10.05 |



