
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 딥러닝
- regression
- LG Aimers
- GPT-4
- ChatGPT
- LG Aimers 4th
- AI
- supervised learning
- LG
- OpenAI
- 해커톤
- 지도학습
- 오블완
- 분류
- PCA
- 회귀
- Machine Learning
- gpt
- deep learning
- 티스토리챌린지
- LLM
- 머신러닝
- Classification
- Today
- Total
SYDev
Chapter 04-1: 로지스틱 회귀 본문
로지스틱 회귀 알고리즘을 이용해 다중 분류 문제를 해결해보자.
다중 분류(multi-class classification)
- 다중 분류: 타깃 데이터에 2개 이상의 클래스가 포함된 분류 문제를 의미한다.
로지스틱 회귀(logistic regression)
- 로지스틱 회귀: 회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1사이의 값으로 예측해주고, 그 확률에 따라 해당 데이터가 속하는 범주를 분류해주는 알고리즘이다. -> 회귀를 사용하긴 하지만 결국엔 분류 알고리즘!
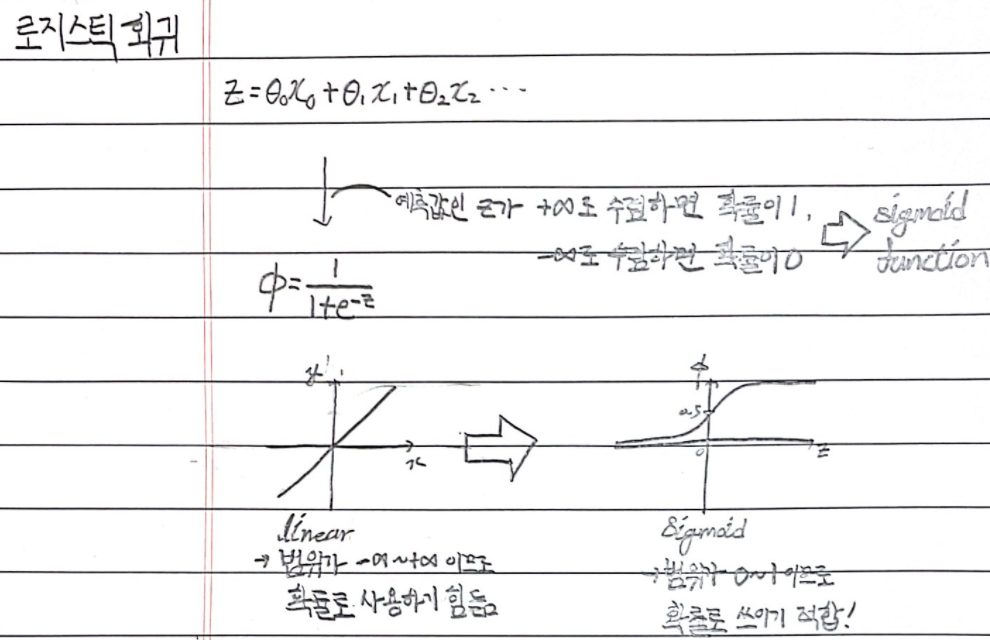
위 그림과 같이 선형 회귀의 경우에는 예측값을 그대로 확률로 사용하기에 무리가 있다.
->> 선형 방정식을 학습한 z값을 구해서, 이를 시그모이드 함수에 대입해 0~1 사이의 확률을 얻는다.
로지스틱 회귀의 hyper parameter C
- 로지스틱 회귀의 비용함수는 아래의 형태를 가진다
- Λ는 로지스틱 회귀의 hyper parameter인데, 로지스틱 회귀 모델에서는 이의 역수인 C를 조정한다.
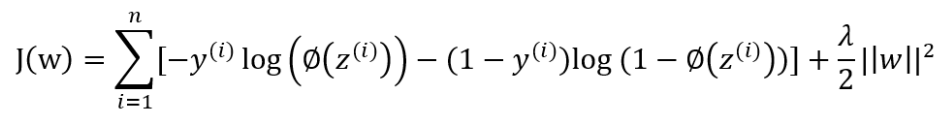
로지스틱 회귀의 penalty 매개변수
- LogisticRegression의 매개변수 penalty는 L1규제와 L2규제를 선택할 수 있고, L2규제가 디폴트이다.
- L1규제는 도움이 되지 않는 계수를 0으로 학습하도록 유도하기 때문에, 중복되지 않는 최소한의 유용한 features 를 선택할 때 사용된다.
소프트맥스 함수
- 소프트 맥스 함수는 클래스가 여러 개 존재할 때, 각각의 클래스의 z값을 확률로 변환하는 함수이다.
- 클래스가 7개 있을 때, 각각의 확률은 다음과 같이 계산한다.
e_sum = e^(z1) + e^(z2) +....+e^(z7)
s1 = e^(z1) / e_sum, s2 = e^(z2) / e_sum, ... , s7 = e^(z7) / e_sum
로지스틱 회귀를 이용한 다중 분류의 해결
KNN을 이용한 확률 예측
- 위에서는 로지스틱 회귀를 이용해 각 샘플이 클래스에 속할 확률을 구할 수 있다고 언급했는데, 그 이전에 KNN을 이용해 확률을 구해보자.
['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']
0.8907563025210085
0.85
['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']
[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]]-> 표기 가능한 확률은 0, 0.3333, 0.6667, 1이 전부이므로 정확하지 못하다.
+ 그렇다면 k값을 바꿔보면 어떻게 될까?
0.7983193277310925
0.825
['Perch' 'Smelt' 'Perch' 'Perch' 'Perch']
[[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.1111 0. 0. 0.8889 0. ]
[0. 0. 0.5556 0.4444 0. 0. 0. ]
[0. 0. 0.5556 0. 0.3333 0. 0.1111]
[0. 0. 0.8889 0. 0.1111 0. 0. ]]
0.6470588235294118
0.725
['Perch' 'Smelt' 'Perch' 'Perch' 'Perch']
[[0. 0.05 0.65 0. 0.3 0. 0. ]
[0. 0.1 0.3 0. 0.15 0.45 0. ]
[0. 0. 0.45 0.25 0.25 0. 0.05]
[0. 0.15 0.5 0. 0.3 0. 0.05]
[0. 0. 0.65 0. 0.35 0. 0. ]]-> k값을 올려봤자 모델의 정확도만 떨어지고 확률의 다양성도 이전과 큰 차이는 없어보인다.
로지스틱 회귀를 이용한 확률 예측
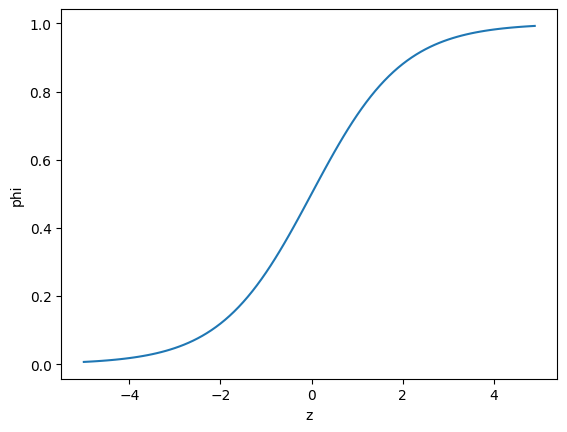
-> 로지스틱 함수를 이용한 값은 연속적이며, 0~1의 범위를 가지기 때문에 확률로 사용하기에 적합해보인다!
로지스틱 회귀로 이진 분류 수행
['A' 'C']
['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
[[0.99759855 0.00240145]
[0.02735183 0.97264817]
[0.99486072 0.00513928]
[0.98584202 0.01415798]
[0.99767269 0.00232731]]-> 첫 번째 열이 음성 클래스에 대한 확률, 두 번째 열이 양성 클래스에 대한 확률
['Bream' 'Smelt']-> 양성 클래스는 도미(smelt)
[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]-> 로지스틱 회귀 모델이 학습한 방정식:
$z = -0.404*(Weight) - 0.576*(Length) - 0.663*(Diagonal)$
$ - 1.013*(Height) - 0.732*(Width) - 2.161 $
여기서 나온 z값을 시그모이드 함수에 넣어주면 확률을 얻을 수 있다.
[-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
[0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
로지스틱 회귀로 다중 분류 수행
0.9327731092436975
0.925
['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
(7, 5) (7,)-> 클래스마다 z값을 각각 계산
[[ -6.5 1.03 5.16 -2.73 3.34 0.33 -0.63]
[-10.86 1.93 4.77 -2.4 2.98 7.84 -4.26]
[ -4.34 -6.23 3.17 6.49 2.36 2.42 -3.87]
[ -0.68 0.45 2.65 -1.19 3.26 -5.75 1.26]
[ -6.4 -1.99 5.82 -0.11 3.5 -0.11 -0.71]]
[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
참고자료
- 박해선, <혼자 공부하는 머신러닝+딥러닝>, 한빛미디어(주), 2022.2.4
- https://hleecaster.com/ml-logistic-regression-concept/
로지스틱회귀(Logistic Regression) 쉽게 이해하기 - 아무튼 워라밸
본 포스팅에서는 머신러닝에서 분류 모델로 사용되는 로지스틱 회귀 알고리즘에 대한 개념을 최대한 쉽게 소개한다. (이전에 선형회귀에 대한 개념을 알고 있다면 금방 이해할 수 있는 수준으
hleecaster.com
5-6. 로지스틱 회귀분석(Logistic Regression)
로지스틱 회귀분석 지금까지 학습한 선형 회귀분석 단순/다중은 모두 종속변수Y가 연속형이었다. 로지스틱회귀분석은 종속변수가 범주형이면서 0 or 1인 경우 사용하는 회귀분석이다. 로지스틱
nittaku.tistory.com
[라이트 머신러닝]Session 7. 로지스틱 회귀(logistic regression)
이전까지 설명했던 퍼셉트론 알고리즘은 간단하고 좋지만 클래스가 선형적으로 구분되지 않을 때는 수렴하지 않습니다. 따라서, 더 강력한 알고리즘 로지스틱 회귀를 설명하려고 합니다. 이름
dnai-deny.tistory.com
Logistic Regression(1) [내가 공부한 머신러닝 #11.]
이전시간까지는 오질나게 Linear 모델로 Regression만 했었죠!?!?! 일반적인 Linear Regression에 L2...
blog.naver.com
앤드류 응의 머신러닝(6-4):로지스틱 회귀 비용함수
온라인 강의 플랫폼 코세라의 창립자인 앤드류 응 (Andrew Ng) 교수는 인공지능 업계의 거장입니다. 그가 스탠퍼드 대학에서 머신 러닝 입문자에게 한 강의를 그대로 코세라 온라인 강의 (Coursera.org
brunch.co.kr
Logistic regression with L1, L2 regularization and keyword extraction
Logistic regression 은 feature X 와 클래스 Y 간의 관계인 클래스의 대표벡터를 coefficients 에 학습합니다. 대표벡터 (coefficient) 를 구성하는 값 들은 j 번째 feature, 와 클래스 k 와의 상관성입니다. 때로는
lovit.github.io
'KHUDA 4th > 머신러닝 기초 세션' 카테고리의 다른 글
| Chapter 04-2: 확률적 경사 하강법 (0) | 2023.08.14 |
|---|---|
| 경사 하강법 (0) | 2023.08.13 |
| [KHUDA 4th] 머신러닝 2주차 기초 세션 (08.10) (1) | 2023.08.10 |
| 정규화 모델(릿지,라쏘 모델) (0) | 2023.08.09 |
| Chapter 03-3: 특성 공학과 규제 (0) | 2023.08.04 |



