
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 회귀
- supervised learning
- LLM
- 티스토리챌린지
- deep learning
- 딥러닝
- 지도학습
- LG
- 분류
- PCA
- Machine Learning
- Classification
- GPT-4
- regression
- LG Aimers
- gpt
- 오블완
- AI
- 해커톤
- OpenAI
- 머신러닝
- ChatGPT
- LG Aimers 4th
Archives
- Today
- Total
SYDev
[Data Structure] Chapter 13-1: 빠른 탐색을 보이는 해쉬 테이블 본문
Data Structure & Algorithm/Data Structure
[Data Structure] Chapter 13-1: 빠른 탐색을 보이는 해쉬 테이블
시데브 2023. 9. 17. 17:31빠른 탐색의 성능을 보이는 테이블 자료구조와 테이블에 의미를 부여하는
해쉬 함수를 이해하고, 두 개념이 합쳐진 해쉬 테이블을 구현해보자.
테이블 자료구조의 이해
- 테이블(Table): 저장되는 데이터의 키(key)와 값(value)이 하나의 쌍을 이루는 자료 구조를 의미한다.
- 키(key)가 존재하지 않는 '값'은 저장할 수 없다. 그리고 모든 키는 중복되지 않는다.
- 하나의 키(key)에 대응되는 값(value)는 하나이기 때문에, 테이블 자료구조의 탐색 연산은 $O(1)$의 시간 복잡도를 가진다.

배열을 기반으로 하는 테이블
#include <stdio.h>
typedef struct _empInfo
{
int empNum;
int age;
} EmpInfo;
int main(void)
{
EmpInfo empInfoArr[1000];
EmpInfo ei;
int eNum;
printf("사번과 나이 입력: ");
scanf("%d %d", &(ei.empNum), &(ei.age));
empInfoArr[ei.empNum] = ei;
printf("확인하고픈 직원의 사번 입력: ");
scanf("%d", &eNum);
ei = empInfoArr[eNum];
printf("사번 %d, 나이 %d \n", ei.empNum, ei.age);
return 0;
}사번과 나이 입력: 0917
23
확인하고픈 직원의 사번 입력: 0917
사번 917, 나이 23
- 이와 같은 형태의 테이블에서는 고유번호의 범위가 커질수록 큰 배열이 필요해진다.
- 이런 문제를 해결해주는 것이 '해쉬' 개념이다.
해쉬 함수와 충돌 문제
해쉬 함수
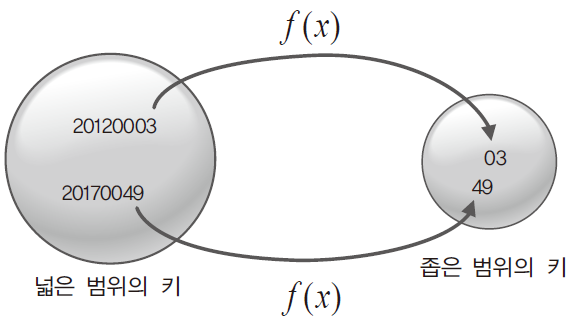
해쉬 함수는 다음 두 가지 문제를 해결할 수 있다.
- key의 범위가 배열의 인덱스 값으로 사용하기에 적당하지 않다.
- 직원 고유번호의 범위를 수용할 수 있는 매우 큰 배열이 필요하다.
위 예제에 해쉬 함수를 추가하여 다시 구현해보자.
#include <stdio.h>
typedef struct _empInfo
{
int empNum;
int age;
} EmpInfo;
int GetHashValue(int empNum)
{
return empNum % 100;
}
int main(void)
{
EmpInfo empInfoArr[100];
EmpInfo emp1 = {20120003, 42};
EmpInfo emp2 = {20130012, 33};
EmpInfo emp3 = {20170049, 27};
EmpInfo r1, r2, r3;
empInfoArr[GetHashValue(emp1.empNum)] = emp1;
empInfoArr[GetHashValue(emp2.empNum)] = emp2;
empInfoArr[GetHashValue(emp3.empNum)] = emp3;
r1 = empInfoArr[GetHashValue(20120003)];
r2 = empInfoArr[GetHashValue(20130012)];
r3 = empInfoArr[GetHashValue(20170049)];
printf("사번 %d, 나이 %d \n", r1.empNum, r1.age);
printf("사번 %d, 나이 %d \n", r2.empNum, r2.age);
printf("사번 %d, 나이 %d \n", r3.empNum, r3.age);
return 0;
}사번 20120003, 나이 42
사번 20130012, 나이 33
사번 20170049, 나이 27
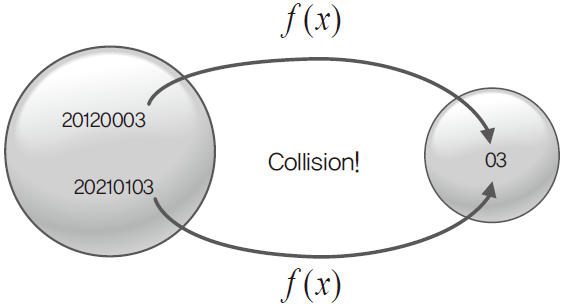
충돌 문제
다음과 같이 해쉬 함수를 거쳤을 때, 중복되는 해쉬 값이 출력되는 것을 충돌(collision) 문제라고 한다.
어느 정도 갖춰진 테이블과 해쉬의 구현
파일명: Person.h
#ifndef __PERSON_H__
#define __PERSON_H__
#define STR_LEN 50
typedef struct _person
{
int ssn; //주민등록번호
char name[STR_LEN];
char addr[STR_LEN];
} Person;
int GetSSN(Person * p);
void ShowPerInfo(Person * p);
Person * MakePersonData(int ssn, char * name, char * addr);
#endif
파일명: Person.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "Person.h"
int GetSSN(Person * p)
{
return p->ssn;
}
void ShowPerInfo(Person * p)
{
printf("주민등록번호: %d \n", p->ssn);
printf("이름: %s \n", p->name);
printf("주소: %s \n\n", p->addr);
}
Person * MakePersonData(int ssn, char * name, char * addr)
{
Person * newP = (Person*)malloc(sizeof(Person));
newP->ssn = ssn;
strcpy(newP->name, name);
strcpy(newP->addr, addr);
return newP;
}
파일명: Slot.h
#ifndef __SLOT_H__
#define __SLOT_H__
#include "Person.h"
typedef int Key; //주민등록번호
typedef Person * Value;
enum SlotStatus {EMPTY, DELETED, INUSE}; //슬롯의 상태를 나타내는 열거형 선언
typedef struct _slot
{
Key key;
Value val;
enum SlotStatus status;
} Slot;
#endif
파일명: Table.h
#ifndef __TABLE_H__
#define __TABLE_H__
#include "Slot.h"
#define MAX_TBL 100
typedef int HashFunc(Key k); //책에 잘못 써있음, 아래에서 HashFunc을 받을 때 *를 이용하기 때문에 여기선 그냥 함수의 형태로 와야 함
/***
typedef int HashFunc(Key k);
위와 같은 선언에 대해서는 이후에 아래와 같이 이용할 수 있음
MyHashFunc이라는 함수가 선언되었다고 가정
HashFunc * f = MyHashFunc
혹은 MyFunc(HashFunc * f); 형태로 매개변수로도 받을 수 있음
***/
typedef struct _table
{
Slot tbl[MAX_TBL];
HashFunc * hf;
} Table;
void TBLInit(Table * pt, HashFunc * f);
void TBLInsert(Table * pt, Key k, Value v);
Value TBLDelete(Table * pt, Key k);
Value TBLSearch(Table * pt, Key k);
#endif-> 책 오탈자로 한참을 찾았다.. 포인터 개념을 확실히 숙지하면 헷갈리지 않을 문제!
파일명: Table.c
#include <stdio.h>
#include <stdlib.h>
#include "Table.h"
void TBLInit(Table * pt, HashFunc * f)
{
int i;
for(i=0; i<MAX_TBL; i++)
(pt->tbl[i]).status = EMPTY;
pt->hf = f;
}
void TBLInsert(Table * pt, Key k, Value v)
{
int hv = pt->hf(k); //hash value, hash function
pt->tbl[hv].val = v;
pt->tbl[hv].key = k;
pt->tbl[hv].status = INUSE;;
}
Value TBLDelete(Table * pt, Key k)
{
int hv = pt->hf(k);
if((pt->tbl[hv]).status != INUSE)
{
return NULL;
}
else
{
(pt->tbl[hv]).status = DELETED;
return (pt->tbl[hv]).val;
}
}
Value TBLSearch(Table * pt, Key k)
{
int hv = pt->hf(k);
if((pt->tbl[hv]).status != INUSE)
return NULL;
else
return (pt->tbl[hv]).val;
}
파일명: SimpleHashMain.c
#include <stdio.h>
#include <stdlib.h>
#include "Person.h"
#include "Table.h"
int MyHashFunc(int k)
{
return k % 100;
}
int main(void)
{
Table myTbl;
Person * np;
Person * sp;
Person * rp;
TBLInit(&myTbl, MyHashFunc);
np = MakePersonData(20120003, "Lee", "Seoul");
TBLInsert(&myTbl, GetSSN(np), np);
np = MakePersonData(20130012, "KIM", "Jeju");
TBLInsert(&myTbl, GetSSN(np), np);
np = MakePersonData(20170049, "HAN", "Kangwon");
TBLInsert(&myTbl, GetSSN(np), np);
sp = TBLSearch(&myTbl, 20120003);
if(sp != NULL)
ShowPerInfo(sp);
sp = TBLSearch(&myTbl, 20130012);
if(sp != NULL)
ShowPerInfo(sp);
sp = TBLSearch(&myTbl, 20170049);
if(sp != NULL)
ShowPerInfo(sp);
rp = TBLDelete(&myTbl, 20120003);
if(rp != NULL)
free(rp);
rp = TBLDelete(&myTbl, 20130012);
if(rp != NULL)
free(rp);
rp = TBLDelete(&myTbl, 20170049);
if(rp != NULL)
free(rp);
return 0;
}주민등록번호: 20120003
이름: Lee
주소: Seoul
주민등록번호: 20130012
이름: KIM
주소: Jeju
주민등록번호: 20170049
이름: HAN
주소: Kangwon
좋은 해쉬 함수의 조건
좋은 해쉬 함수는 키의 일부분을 참조하여 해쉬 값을 만들지 않고, 키 전체를 참조하여 해쉬 값을 만든다.

자릿수 선택 방법
- 자릿수 선택(Digit Selection) 방법: 키의 특정 위치에서 중복의 비율이 높거나, 아예 공통으로 들어가는 값이 있다면, 이를 제외한 나머지를 가지고 해쉬 값을 생성하는 방법이다.
자릿수 폴딩 방법
다음과 같이 273419라는 숫자가 있을 때, 두 자리씩 숫자를 접어서 겹치는 숫자를 모두 더하여, 해쉬 값을 얻어내는 방법이 자릿수 폴딩(Digit Folding) 방법이다.

이외에도 폴딩의 과정에서 덧셈 대신 XOR 연산을 진행하는 방법 등 여러가지 방법이 있으며, 상황에 맞는 적절한 방법을 사용하면 된다.
- 윤성우, <윤성우의 열혈 자료구조>, 오렌지미디어, 2022.04.11
728x90
반응형
'Data Structure & Algorithm > Data Structure' 카테고리의 다른 글
| [Data Structure] Chapter 14: 그래프(Graph) (0) | 2023.09.20 |
|---|---|
| [Data Structure] Chapter 13-2: 충돌(Collision) 문제의 해결책 (0) | 2023.09.18 |
| [Data Structure] Chapter 12: 균형 잡힌 이진 탐색 트리 - AVL 트리 (0) | 2023.09.13 |
| [Data Structure] Chapter 11-2: 이진 탐색 트리 (0) | 2023.09.12 |
| [Data Structure] Chapter 11-1: 탐색의 이해와 보간 탐색 (1) | 2023.09.11 |
'Data Structure & Algorithm/Data Structure' Related Articles
more



