
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 딥러닝
- GPT-4
- LG Aimers
- OpenAI
- 티스토리챌린지
- LG
- 오블완
- supervised learning
- ChatGPT
- 머신러닝
- gpt
- PCA
- 지도학습
- 해커톤
- deep learning
- LG Aimers 4th
- regression
- Classification
- Machine Learning
- LLM
- 분류
- 회귀
- AI
- Today
- Total
SYDev
[Data Structure] Chapter 13-2: 충돌(Collision) 문제의 해결책 본문
[Data Structure] Chapter 13-2: 충돌(Collision) 문제의 해결책
시데브 2023. 9. 18. 15:14테이블의 핵심 주제라 할 수 있는 충돌 문제의 해결책을 몇 가지 알아보고, 구현해보자.
열린 어드레싱 방법
- 열린 어드레싱 방법(open addressing method): 충돌이 발생하면 다른 자리에 대신 저장하는 방법
- 선형 조사법, 이차 조사법, 이중 해쉬가 이에 속한다.
선형 조사법
- 선형 조사법(Linear Probing): 충돌이 발생했을 때 그 옆자리가 비었는지 살펴보고, 비었을 경우 그 자리에 대신 저장하는 방법이다.


옆자리가 비어있지 않을 경우, 옆으로 한 칸 더 이동을 해서 자리를 살핀다.

그러나, 이런 구조는 충돌의 횟수가 증가함에 따라 '클러스터(cluster) 현상(특정 영역에 데이터가 집중적으로 몰리는 현상)'이 발생하기 쉽다.
이런 선형 조사법의 단점을 극복할 수 있는 방법이 이차 조사법이다.
이차 조사법
이차 조사법은 다음과 같은 순서로 조사가 전개된다.
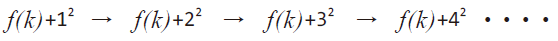
DELETED 상태의 필요성
이전에 테이블을 구현할 때, 슬롯의 상태에 EMPTY, INUSE 뿐만 아니라 DELETED도 포함시켰었다. 이 상태가 필요한 이유는 무엇일까?
HashFunc이 key%7인 상황을 가정해보자. 이때, 키가 2인 데이터 9가 먼저 저장되고 이후에 2가 저장되면 다음과 같이 나열된다.

이때, 9가 삭제되었다고 하자.

여기서 2를 찾으려고 시도할 때, hv가 2인 슬롯이 empty 상태이면 찾으려는 값이 있음에도 조사는 조기에 종료된다.
이런 문제를 해결하기 위해서 DELETED 상태를 포함시켜, 조사의 조기 종료를 방지한다.
이중 해쉬
이중 조사 방법을 적용하면, 물론 선형 조사 방법보다는 낫지만, 그럼에도 같은 슬롯을 중심으로 클러스터 현상이 발생할 확률이 높을 수 밖에 없다.
이런 문제를 해결하는 방법이 바로 두 개의 해쉬 함수를 이용하는 이중 해쉬(Double Hash) 방법이다.
- 1차 해쉬 함수: 키를 근거로 저장 위치를 결정하기 위한 것
- 2차 해쉬 함수: 충돌 발생시 몇 칸 뒤를 살필지 결정하기 위한 것
예를 들어 1차 해쉬 함수의 형태가 다음과 같다고 가정해보자
- 1차 해쉬 함수: $h1(k)=k$ % $15$
2차 해쉬 함수는 위 1차 해쉬 함수를 근거로 다음과 같은 형태가 된다.
- 2차 해쉬 함수: $h2(k) = 1+( k$ % $c )$ (c: 배열의 길이보다 작은 소수(prime number) 중 하나)
- c가 15보다 작은 값인 이유는, 가급적 2차 해쉬 값이 1차 해쉬 값을 넘지 않도록 하기 위함이다.
- c가 소수일 때, 클러스터 현상이 발생할 확률이 통계적 관점에서 현저히 낮아진다.
닫힌 어드레싱 방법
- 닫힌 어드레싱 방법(closed addressing method): 충돌이 발생해도, 같은 자리 저장하는 방법
- 여러 개의 자리를 마련하기 위해서, 배열을 이용하는 방법과 연결 리스트를 이용하는 방법이 있다.
배열을 이용하는 방법
배열을 이용하는 방법은 다음과 같은 형태를 가지는데, 이는 충돌이 발생하지 않을 경우 메모리 낭비가 심하고, 충돌의 최대 횟수를 결정해야 한다는 단점이 있다.

체이닝
다음과 같이 연결 리스트를 이용해 하나의 해쉬 값에 다수의 슬롯을 두는 방법을 체이닝(Chaining)이라고 한다.

체이닝의 구현
- Chapter 13-1에서 구현했던 Person.h, Person.c를 이용한다.
- Chapter 04에서 구현했던 DLinkedList.h, DLinkedList.c를 이용한다.
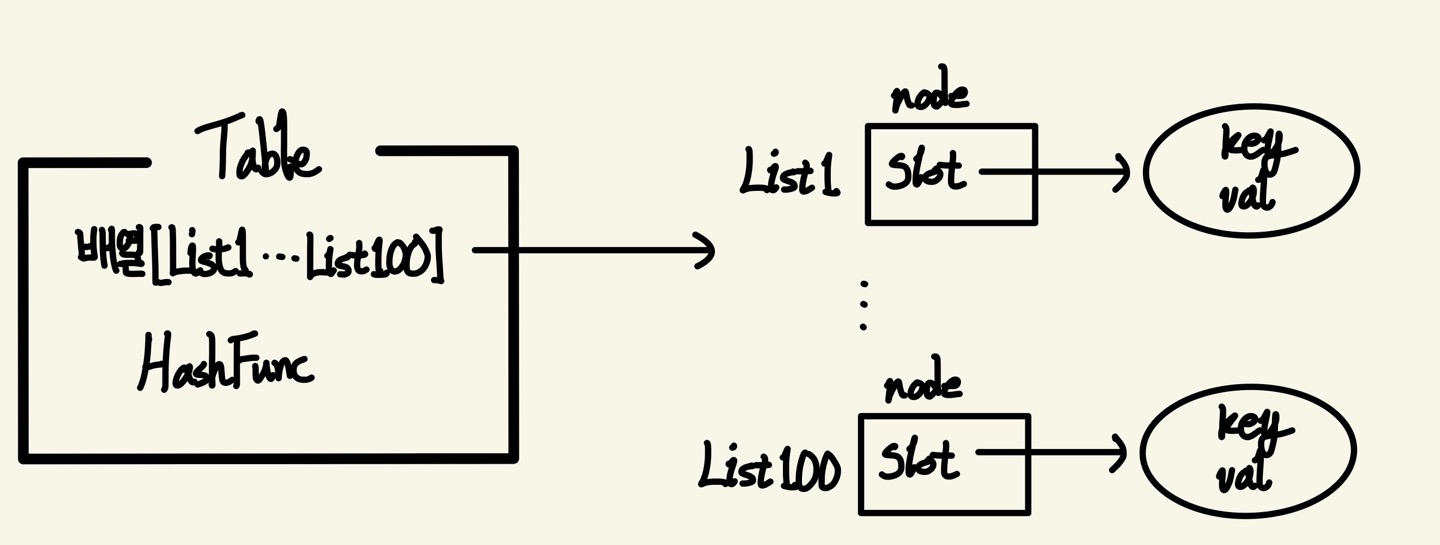
파일명: Slot2.h
#ifndef __SLOT2_H__
#define __SLOT2_H__
#include "Person.h"
typedef int Key;
typedef Person * Value;
typedef struct _slot
{
Key key;
Value val;
} Slot;
#endif>> 닫힌 어드레싱 방법에서는 슬롯의 상태 정보를 표시하는 enum 선언이 필요가 없다.
파일명: Table2.h
#ifndef __TABLE_H__
#define __TABLE_H__
#include "Slot2.h"
#include "DLinkedList.h"
#define MAX_TBL 100
typedef int HashFunc(Key k);
typedef struct _table
{
List tbl[MAX_TBL];
HashFunc * hf;
} Table;
void TBLInit(Table * pt, HashFunc * f);
void TBLInsert(Table * pt, Key k, Value v);
Value TBLDelete(Table * pt, Key k);
Value TBLSearch(Table * pt, Key k);
#endif>> 테이블의 저장소를 Slot형 배열에서 List형 배열로 변경

파일명: Table2.c
Value TBLSearch(Table * pt, Key k) //TBLRemove 과정에서 remove만 빼주면 같음
{
int hv = pt->hf(k);
Slot cSlot;
if(LFirst(&(pt->tbl[hv]), &cSlot))
{
if(cSlot.key == k)
{
return cSlot.val;
}
else
{
while(LNext(&(pt->tbl[hv]), &cSlot))
{
if(cSlot.key == k)
{
return cSlot.val;
}
}
}
}
return NULL;
}>> 키 값 중복 시에 오류가 발생하는 것이지, 해쉬 값과 혼동해서는 안 된다.
파일명: DLinkedList.h
#ifndef __D_LINKED_LIST_H__
#define __D_LINKED_LIST_H__
#include "Slot2.h"
#define TRUE 1
#define FALSE 0
typedef Slot LData;
....
파일명: ChainedTableMain.c
#include <stdio.h>
#include <stdlib.h>
#include "Person.h"
#include "Table2.h"
int MyHashFunc(int k)
{
return k % 100;
}
int main(void)
{
Table myTbl;
Person * np;
Person * sp;
Person * rp;
TBLInit(&myTbl, MyHashFunc);
np = MakePersonData(900254, "LEE", "Seoul");
TBLInsert(&myTbl, GetSSN(np), np);
np = MakePersonData(900139, "KIM", "Jeju");
TBLInsert(&myTbl, GetSSN(np), np);
np = MakePersonData(900827, "HAN", "Kangwon");
TBLInsert(&myTbl, GetSSN(np), np);
sp = TBLSearch(&myTbl, 900254);
if(sp != NULL)
ShowPerInfo(sp);
sp = TBLSearch(&myTbl, 900139);
if(sp != NULL)
ShowPerInfo(sp);
sp = TBLSearch(&myTbl, 900827);
if(sp != NULL)
ShowPerInfo(sp);
rp = TBLDelete(&myTbl, 900254);
if(rp != NULL)
free(rp);
rp = TBLDelete(&myTbl, 900139);
if(rp != NULL)
free(rp);
rp = TBLDelete(&myTbl, 900827);
if(rp != NULL)
free(rp);
return 0;
}주민등록번호: 900254
이름: LEE
주소: Seoul
주민등록번호: 900139
이름: KIM
주소: Jeju
주민등록번호: 900827
이름: HAN
주소: Kangwon
구현한 테이블의 문제점
Value TBLDelete(Table * pt, Key k)
{
. . . .
return NULL;
}
Value TBLSearch(Table * pt, Key k)
{
. . . .
return NULL;
}대상을 찾지 못했을 때 NULL을 반환하는데, NULL은 그 자체로 정수 0이기 때문에, 만약에 Value가 int형이라면 혼동의 여지가 있다.
물론 예제에서는 Value를 포인터 형으로 선언했기 때문에 문제가 없지만, 그렇지 않은 경우에는 다음과 같이 함수호출의 성공여부를 반환값으로 보인다면 문제는 해결된다.
Value TBLDelete(Table * pt, Key k)
{
. . . .
return FALSE;
}
Value TBLSearch(Table * pt, Key k)
{
. . . .
return FALSE;
}
- 윤성우, <윤성우의 열혈 자료구조>, 오렌지미디어, 2022.04.11
'Data Structure & Algorithm > Data Structure' 카테고리의 다른 글
| [Data Structure] Chapter 14: 그래프(Graph) (0) | 2023.09.20 |
|---|---|
| [Data Structure] Chapter 13-1: 빠른 탐색을 보이는 해쉬 테이블 (1) | 2023.09.17 |
| [Data Structure] Chapter 12: 균형 잡힌 이진 탐색 트리 - AVL 트리 (0) | 2023.09.13 |
| [Data Structure] Chapter 11-2: 이진 탐색 트리 (0) | 2023.09.12 |
| [Data Structure] Chapter 11-1: 탐색의 이해와 보간 탐색 (1) | 2023.09.11 |



